1 Compositional semantics

Deep here we mean as deeper understanding of language no NN
2 Compositional semantics alongside syntax
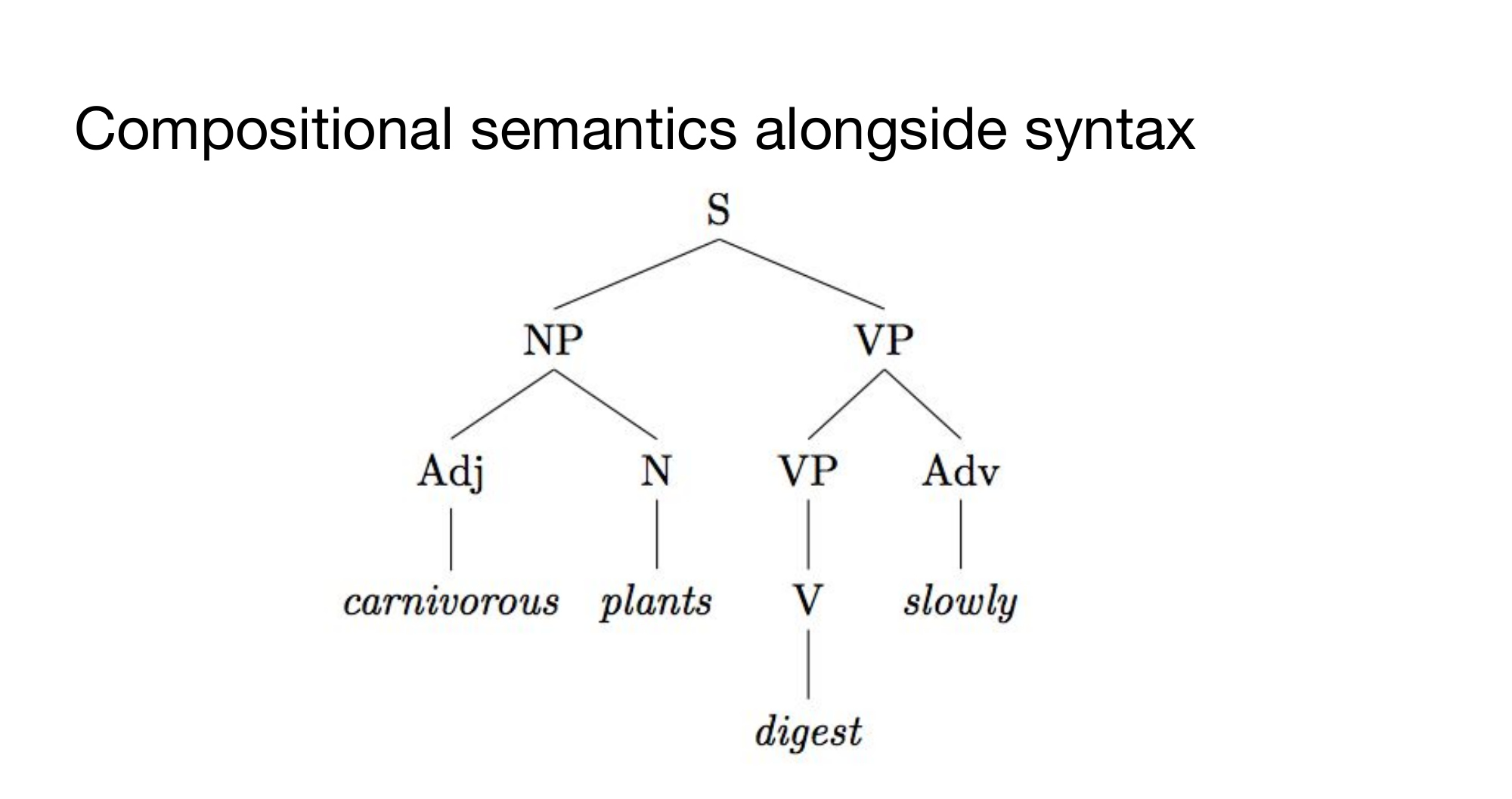
If we want to model semantics alongside syntax. Word meaning then phrase meaning, then sentence meaning.
3 Non-trivial issues with semantic composition

Here in the first i, it refers maybe to a dog. The second one it does not refer to anything. So even if they have same syntax structure they have different meanings
The problem with last one is that even though these phrases can mean soomthing unqiue like the second refere to a person has passed away. Sometimes we may also express that a person just kick the bucket
4 Non-trivial issues with semantic composition

5 Issues with semantic composition

This represent recursion
6 Modelling compositional semantics

These are two modelling frameworks
- Here we do the composition directly in vector space
Unsupervised methods, they are general purpose. They capture the meaning of a word based on the similarity with other words.
- Here you train your representation in a supervised way, which means you need a task to get the learning signal from. For example in sentiment classification.
For instance if you train your representations to sentiment analysis and then you want to do translation this will not work, cause you train on a different task

7 Compositional distributional semantics
These are the all general purpose unsupervised way
The idea come up, we were successful to create word representations, why not phrases, then why not in the sentence level.
If you have a finite vocab you can still create an infinitely amount of sentences
It is unfeseable because you dont have every possible sentence there and create a sentence representation for that. But we can do somthing similar which is, instead of learning sentence representatins directly you would try to use the word representation for the sentences and composed to create a sentence representatio.
In principle you need only word representations for all words which is more doable than getting word representations for all sentences
8 Vector mixture models
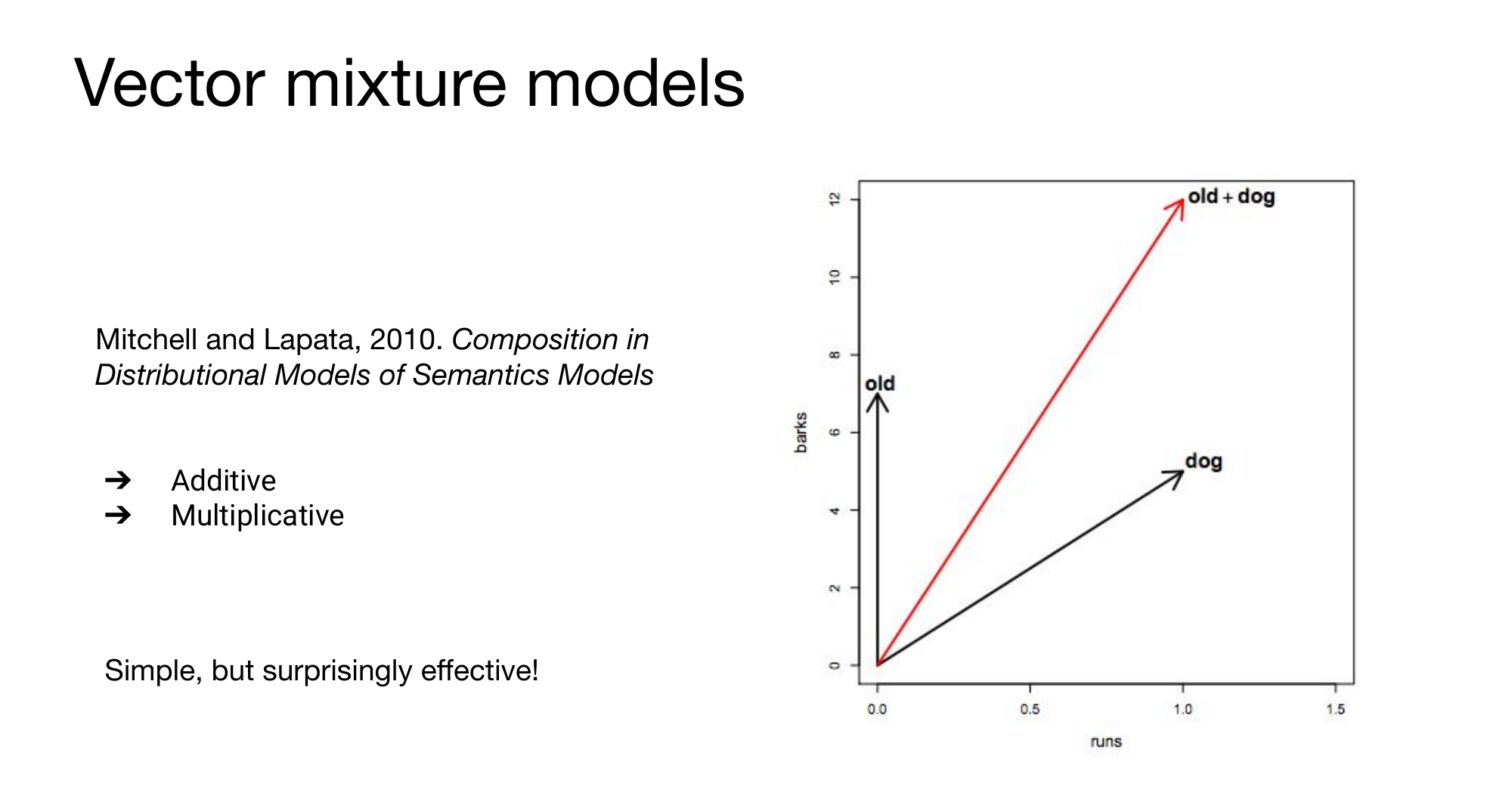
9 Additive and multiplicative models

Because summation is symmetric representation, we get the same representation so this model has a flaw
Prepositions are used flexibly in any position, which means they dont have a strong behavioral profile but the content words they do. For example they appear in the same position they co-ocurr in similar context
10 Lexical function models
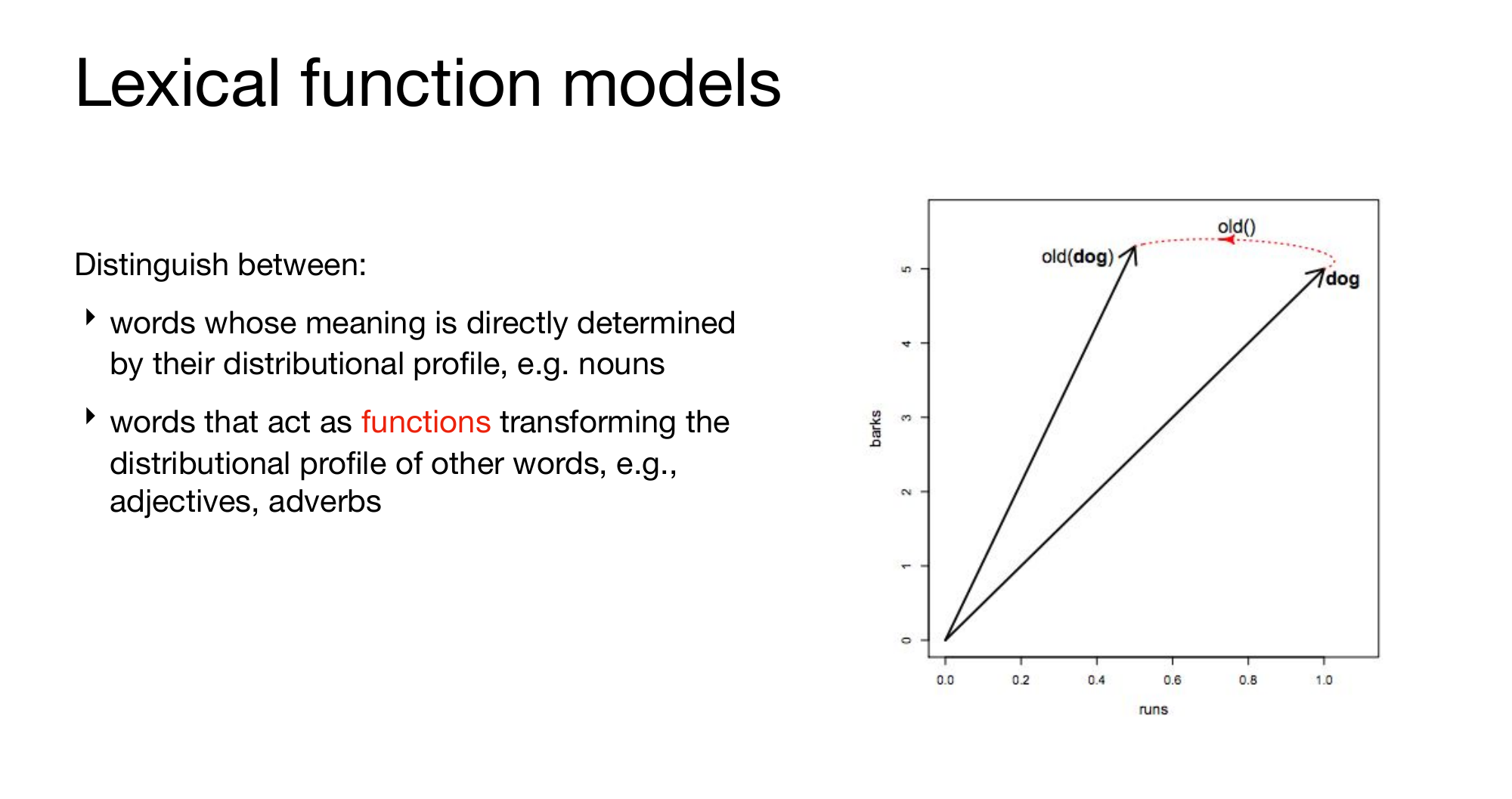
11 Lexical function models

12 Learning adjective matrices

13 Learning adjective matrices

14 Title

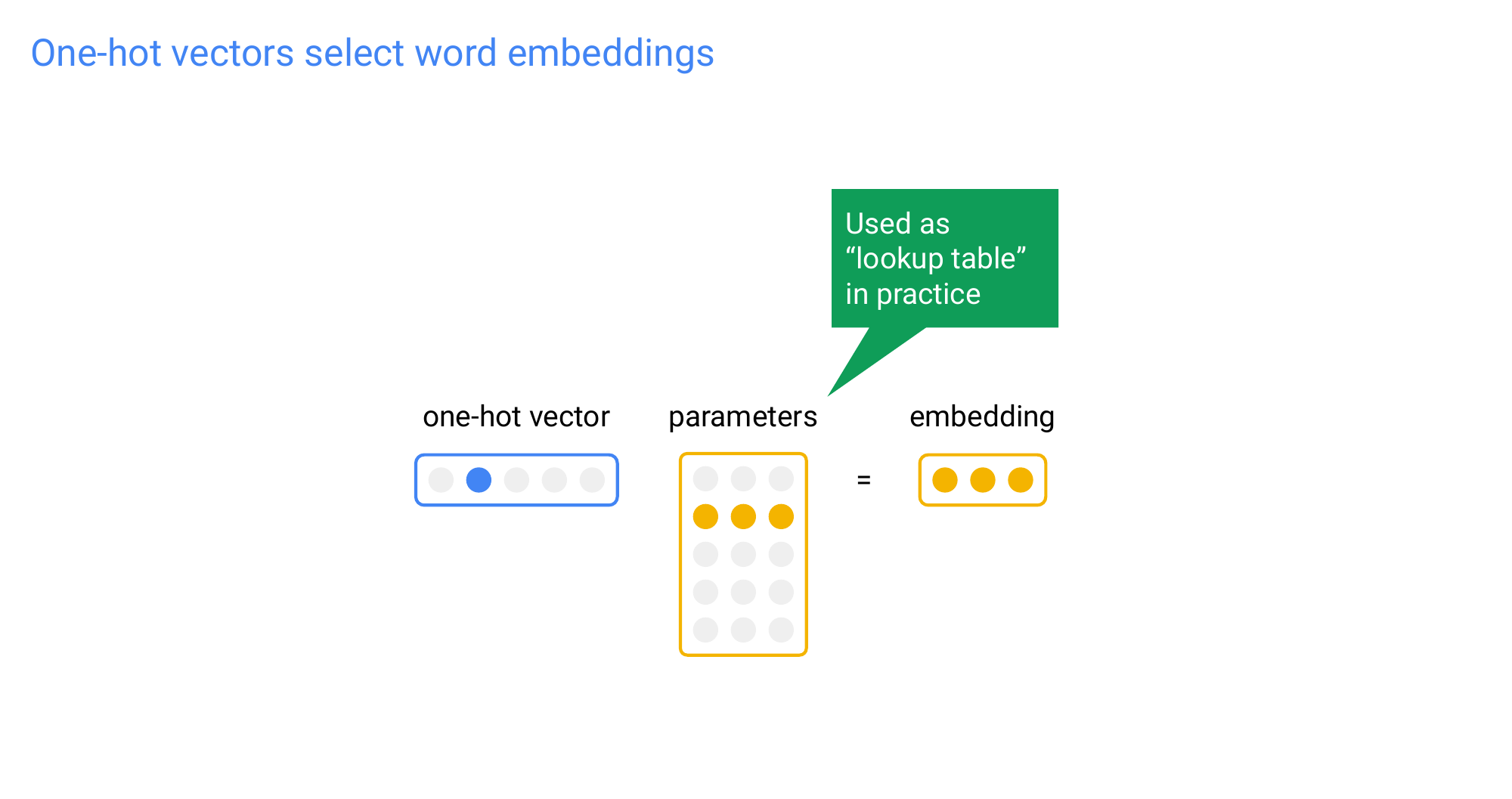
15 Title
16 Title

17 Task: Sentiment classification of movie reviews

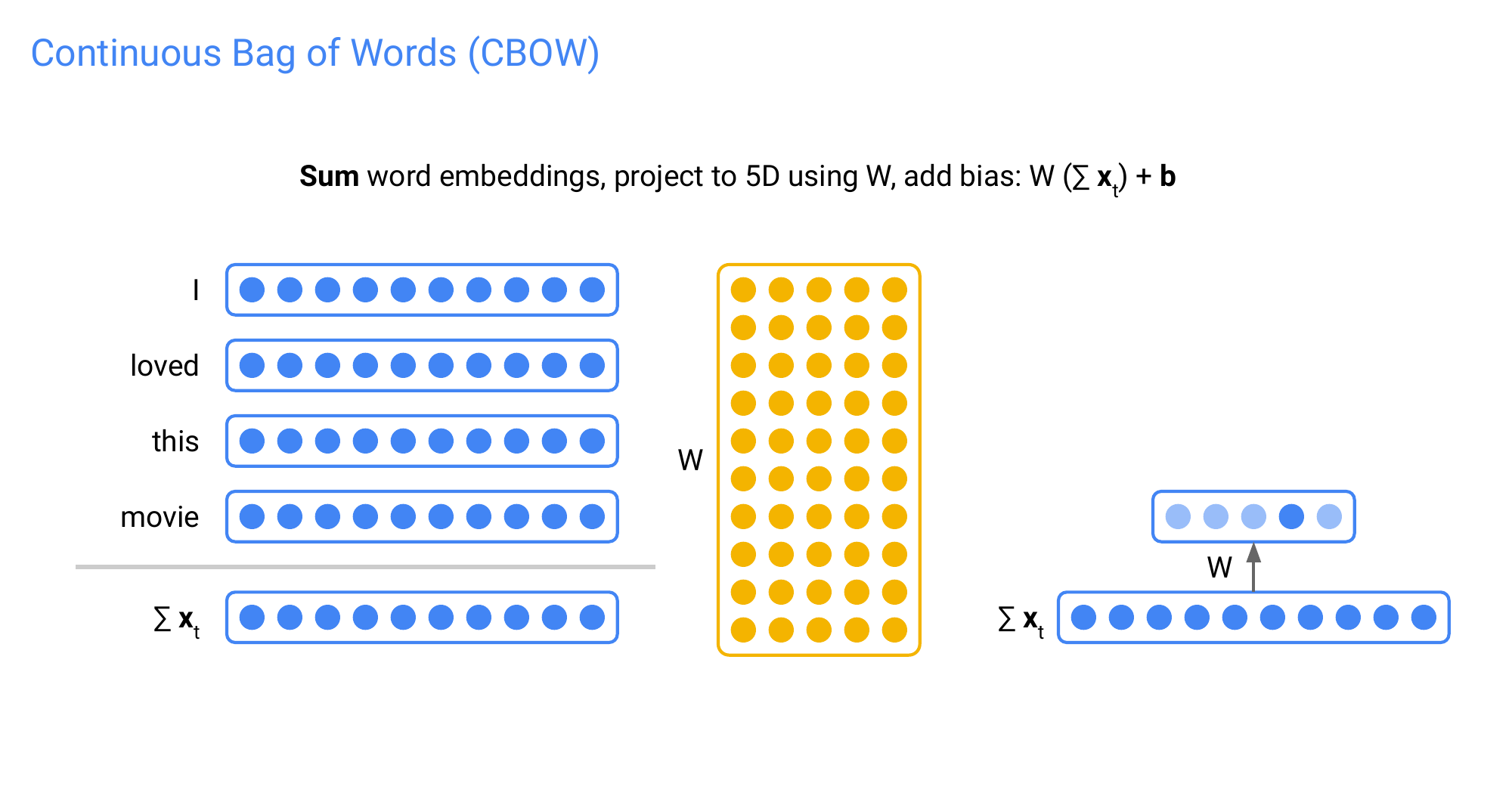
18 Words (and sentences) into vectors
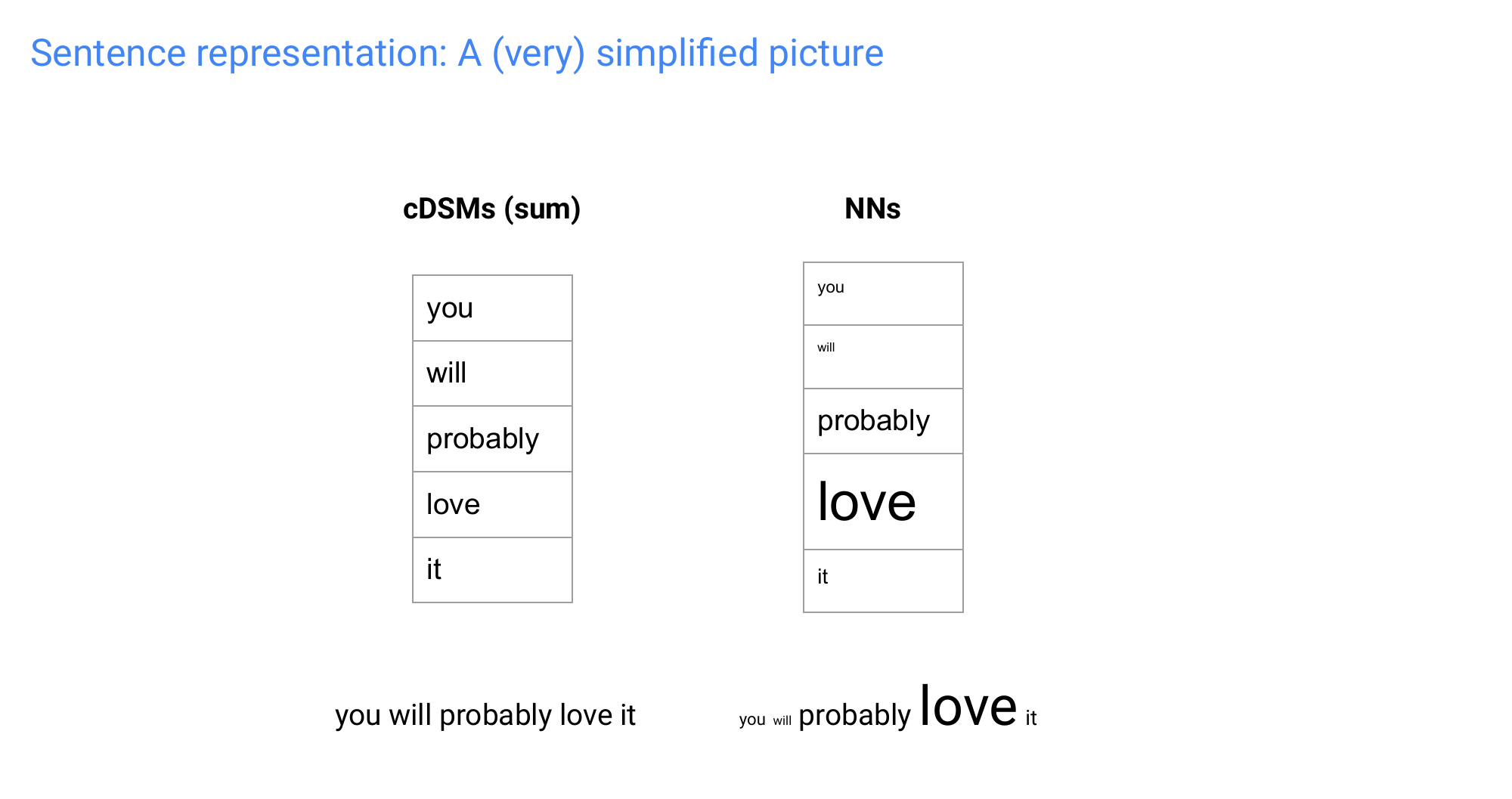
19 Sentence representation: A (very) simplified picture
20 Title

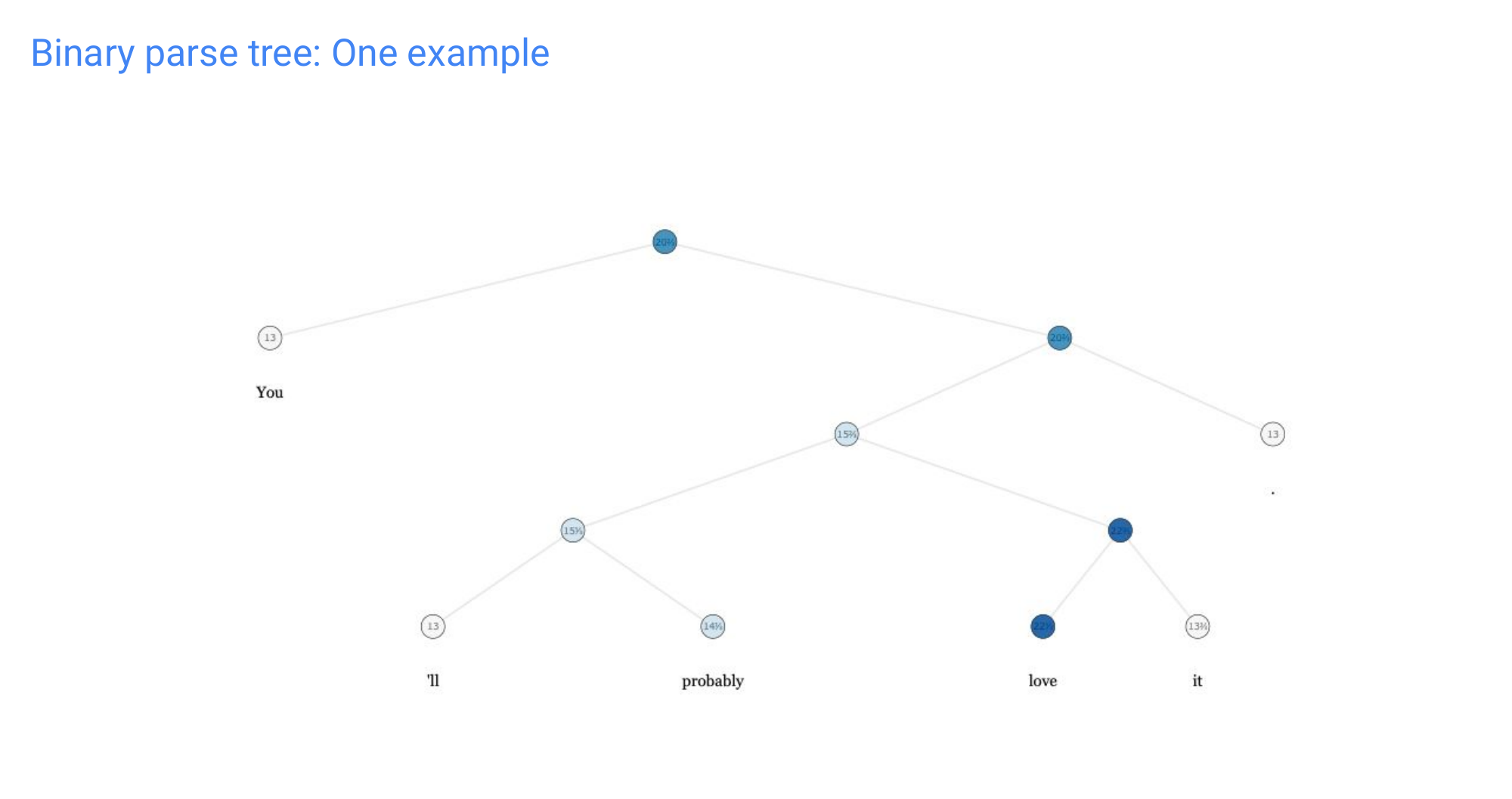
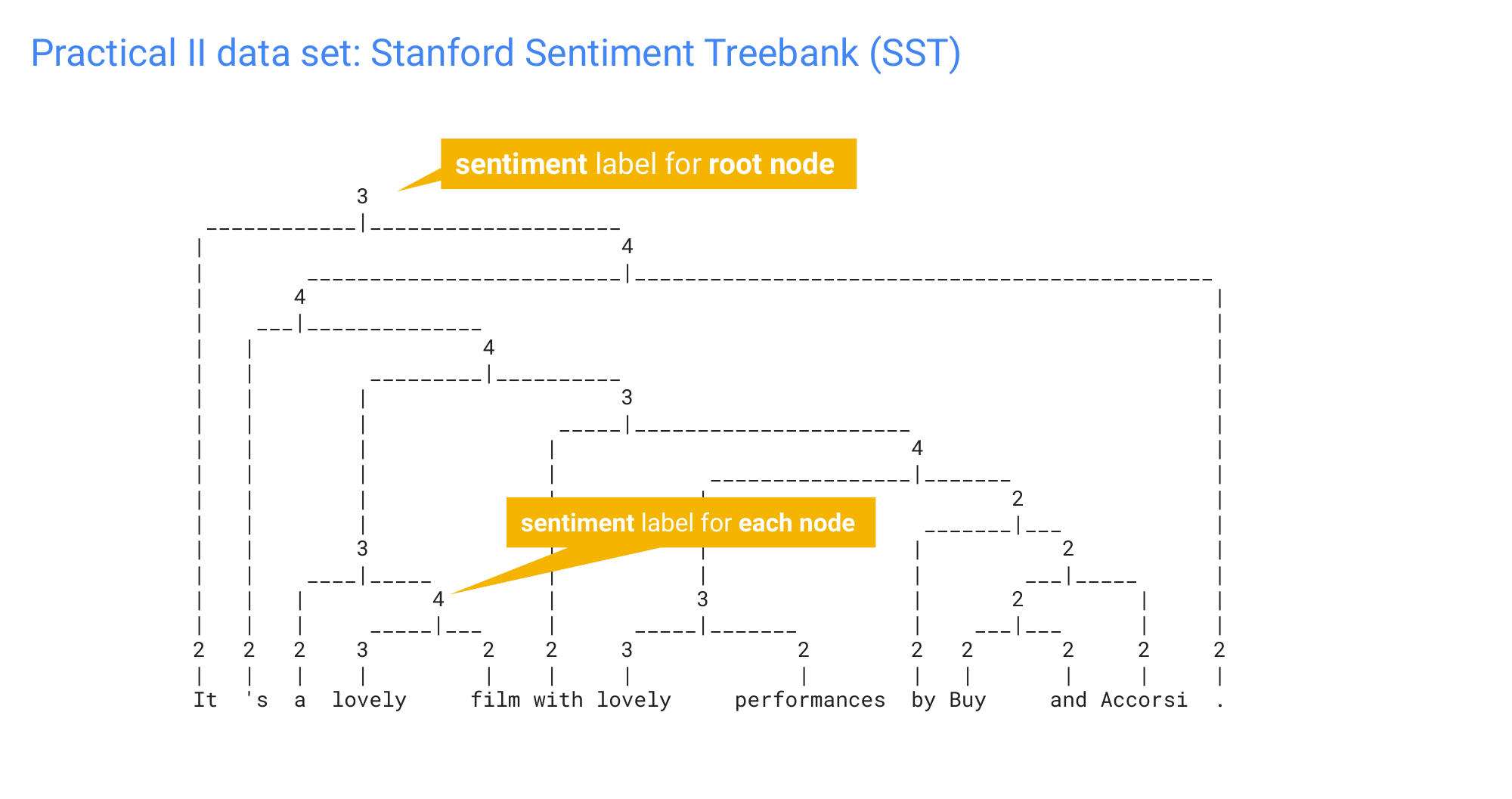
21 Dataset: Stanford Sentiment Treebank (SST)

22 Binary parse tree: One example
23 Title

24 Models

25 First approach: Sentence + Sentiment
26 Title

27 Title

Here we do not model order or syntax
28 Bag of Words

29 Bag of Words

Because you don’t consider order the example in the sentece is the same, so there is a flaw in this model
30 Turning words into numbers

31 One-hot vectors select word embeddings
32 Title

33 Title

Now because the vector representation can squezze more detail in the embedding about the word, then this increase in dimensionality is better
34 Continuous Bag of Words (CBOW)
35 Recall: Matrix Multiplication

36 What about this?
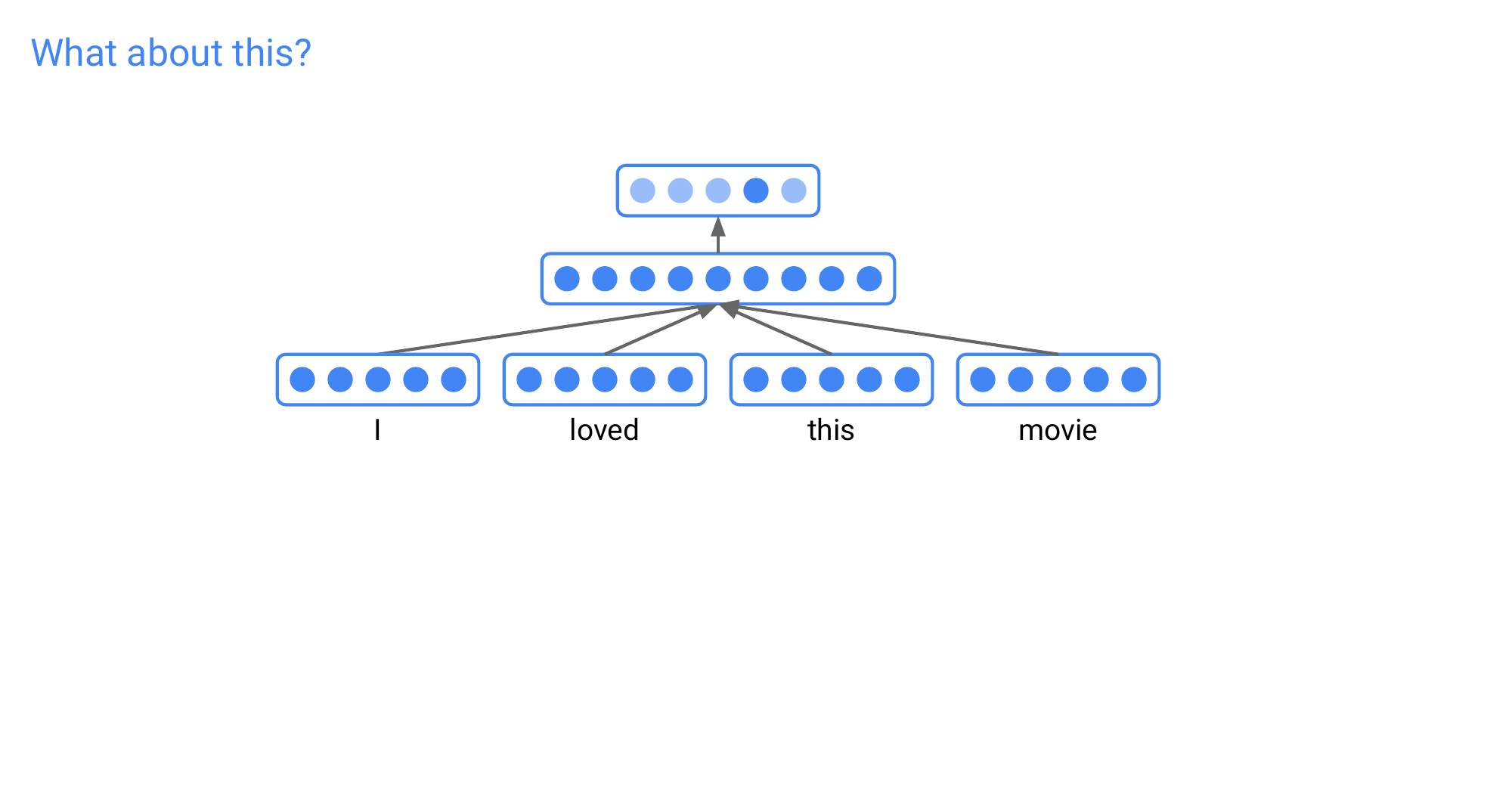
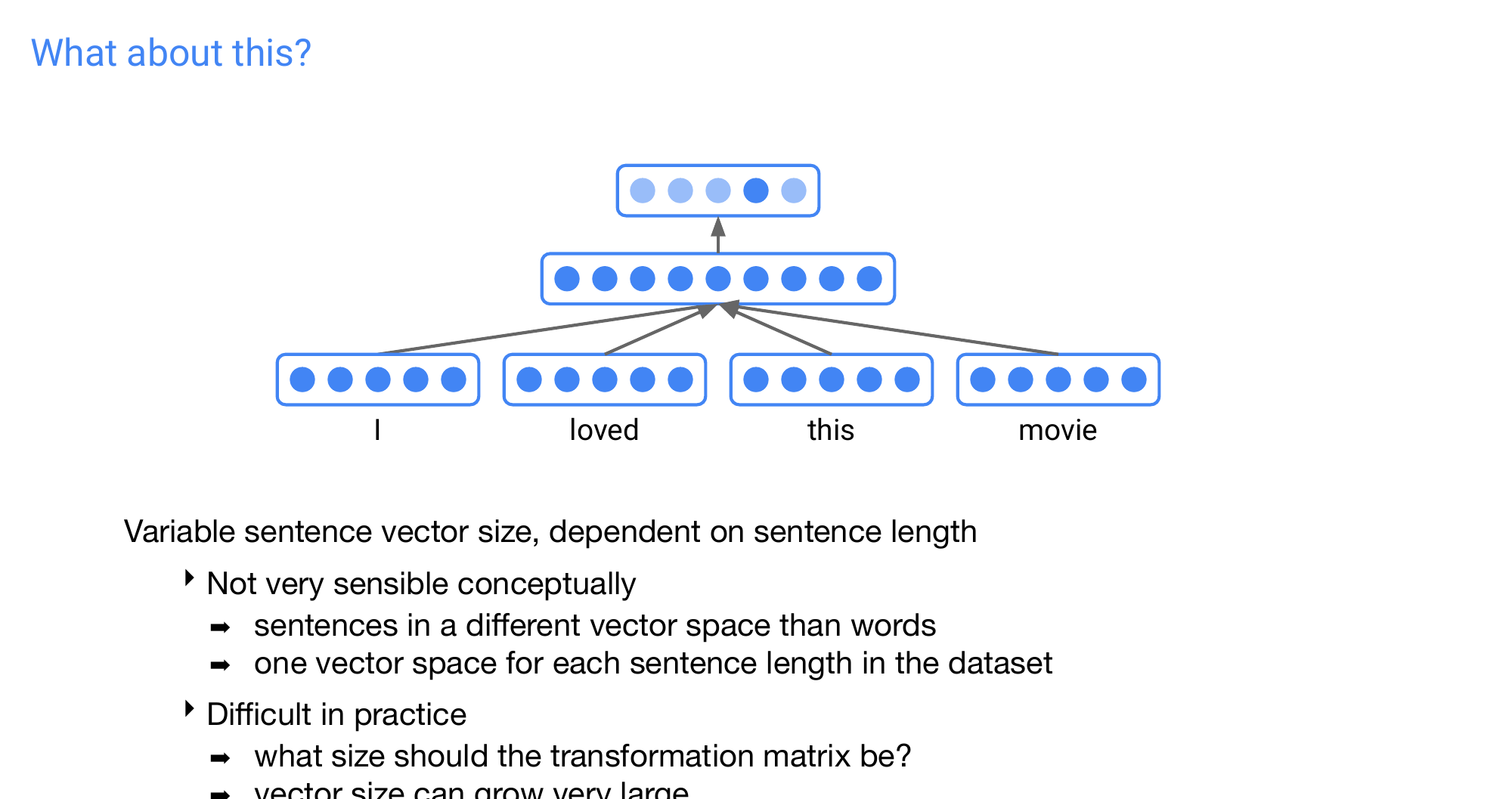
Here the problem of just concatenating is that you dont know the size of the W to multiply because the sentence embeddings are vary in length
37 What about this?
38 Title

39 Title

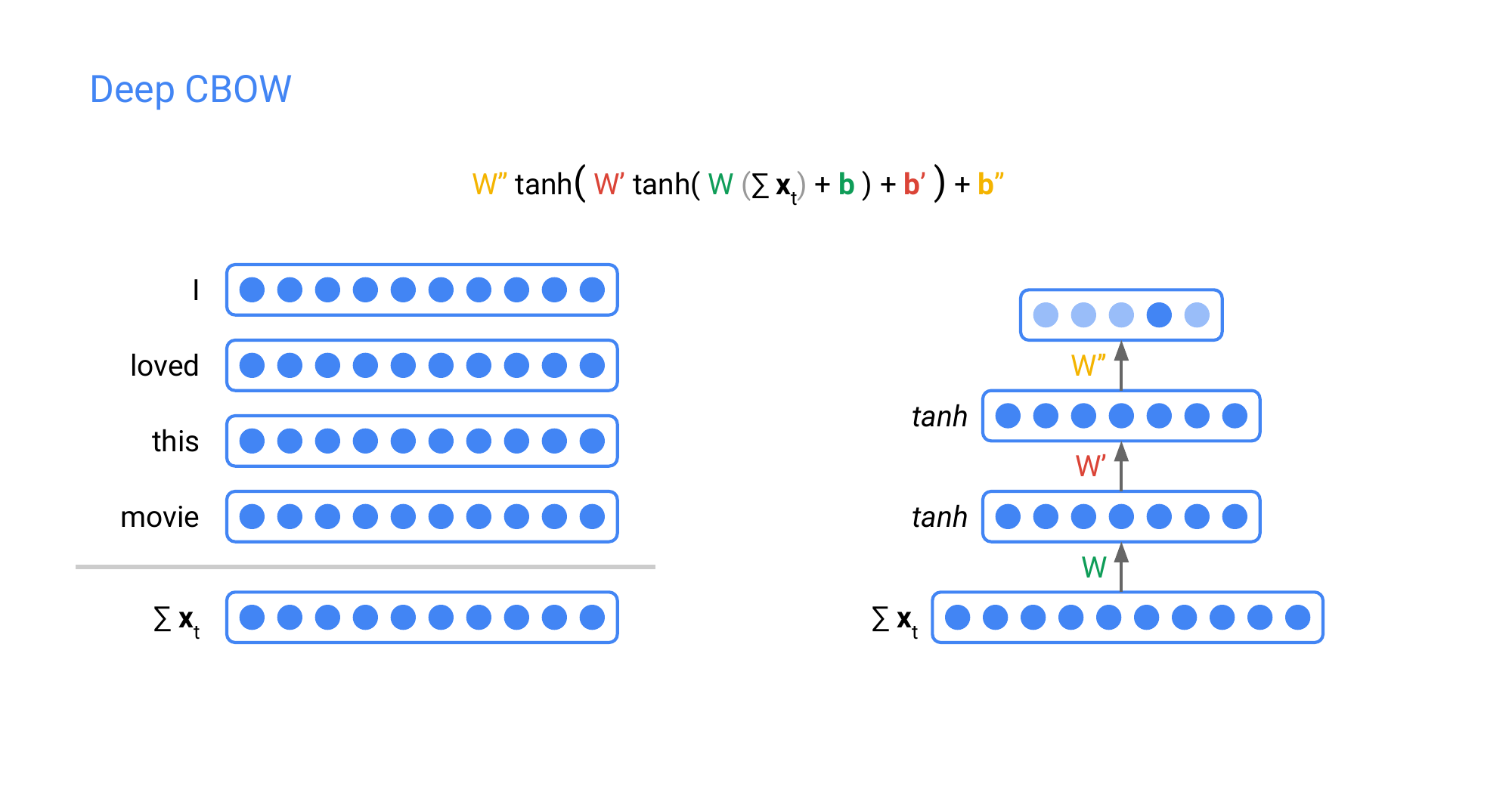
Here we just learn more layers, so more complexity to the model
40 What about this?
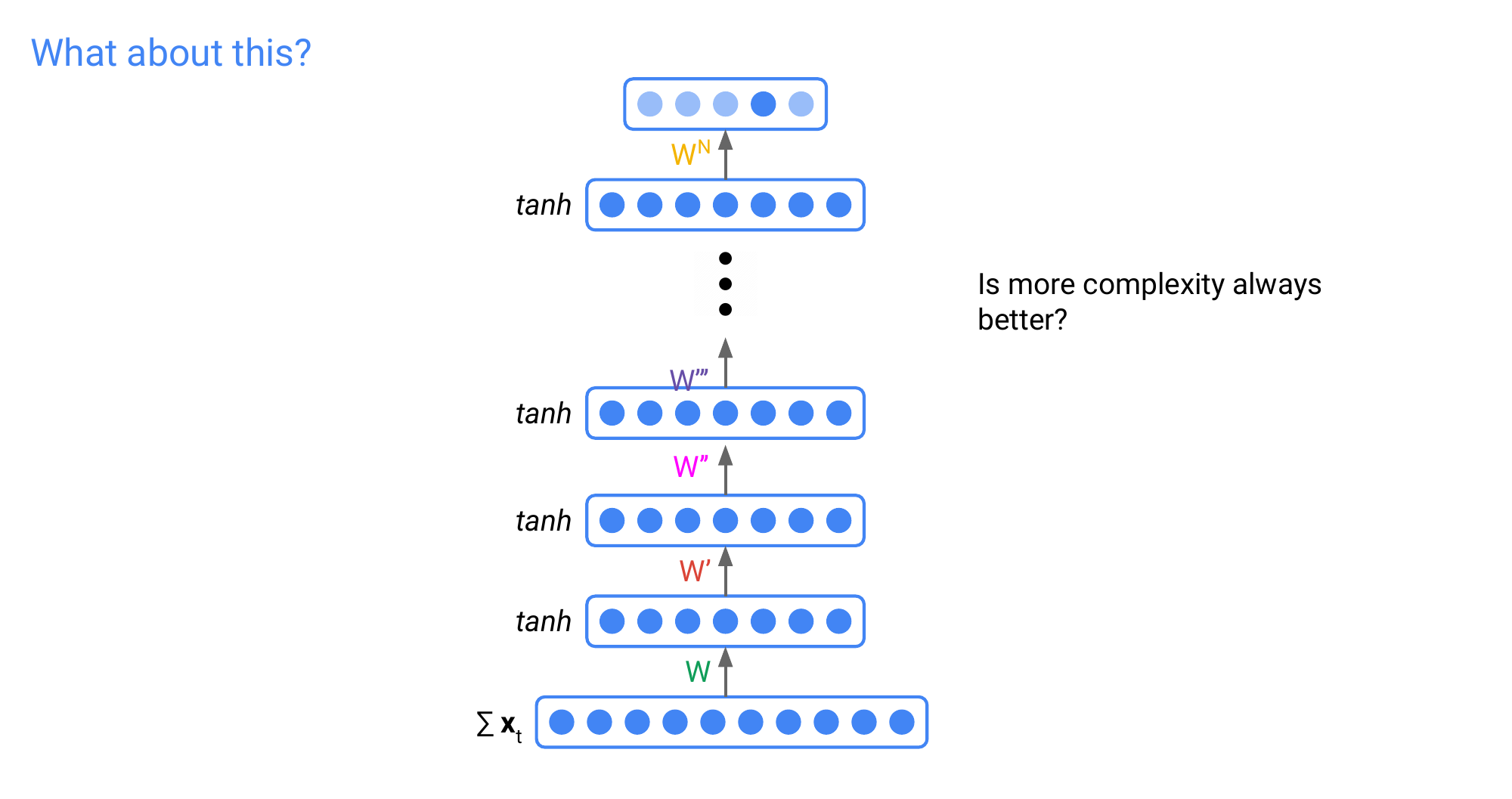
Deeper is not always better because we might start to overfit, and at test time it will not generalize well
41 Question

42 Title

43 Deep CBOW with pretrained embeddings
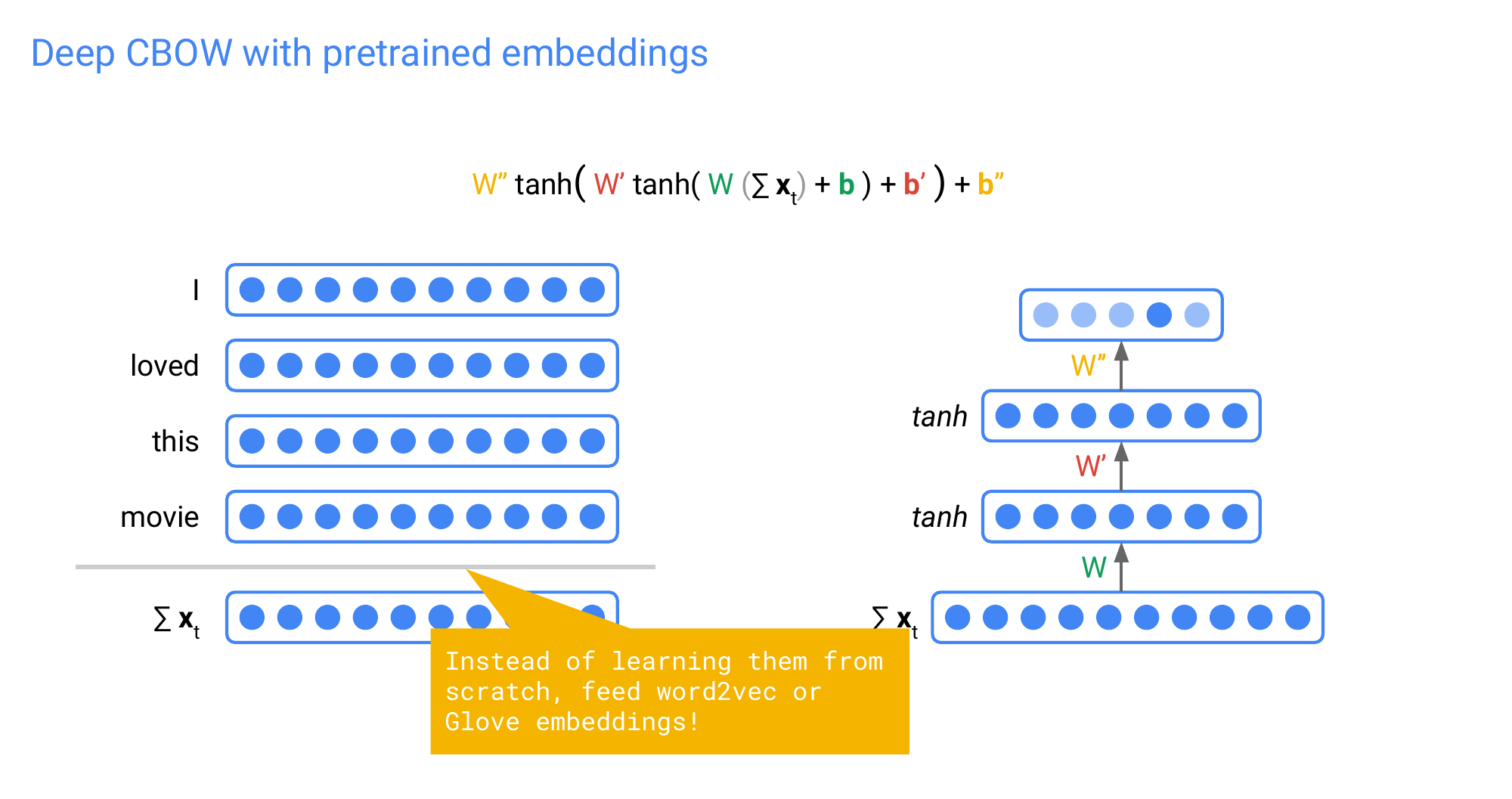
It will be easier if the models already know the word meaning and then it can get the sentoment fo the sentece. Here we have a prior which is our word representation
44 Title

There is two paradigms by using pre-trained embeddings
- You can keep these representations frozen: so not for training
- or you fine-tune the word representations toguether with your task. This means the word represenation becomes more specialized for the task
45 Recap: Training a neural network

46 Cross Entropy Loss

47 Softmax

48 Title

Feed forward NNs were not able to contain word order information, RNN can do it
Here the words would be conditioned in the previous words
49 Introduction: Recurrent Neural Network (RNN)

50 Introduction: Recurrent Neural Network (RNN)
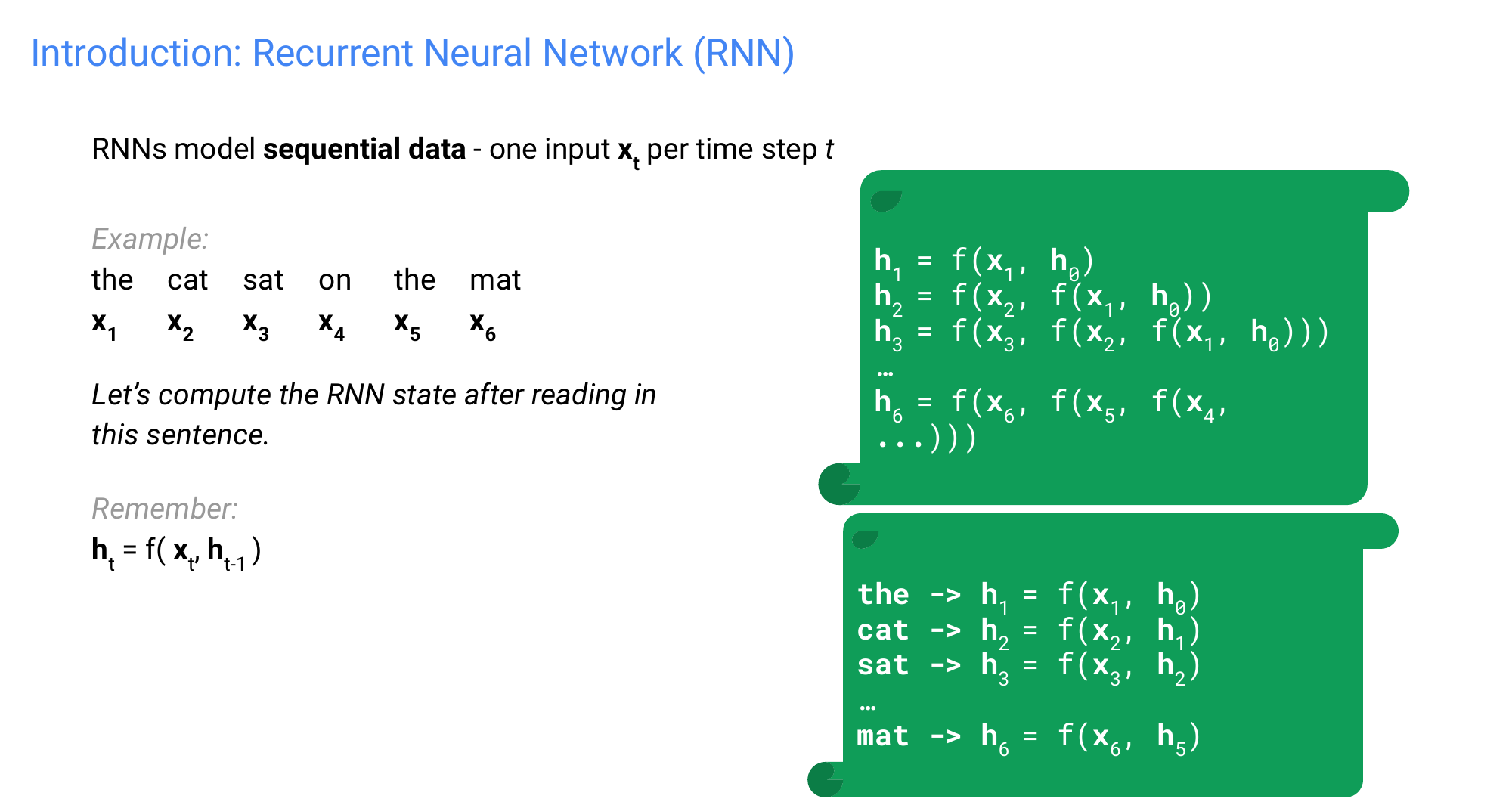
6 words 6 times steps
51 Introduction: Recurrent Neural Network (RNN)
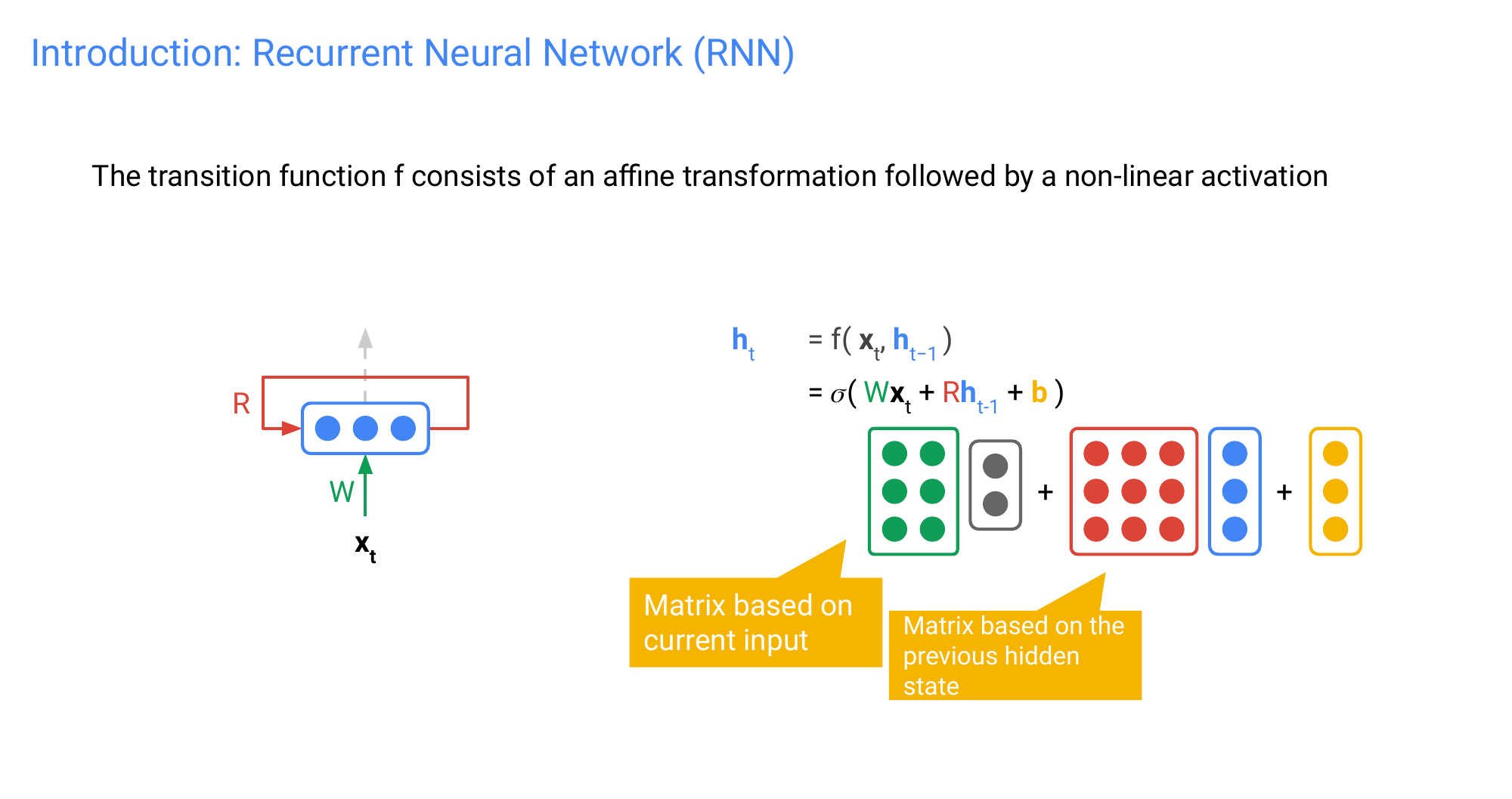
52 Introduction: Unfolding the RNN
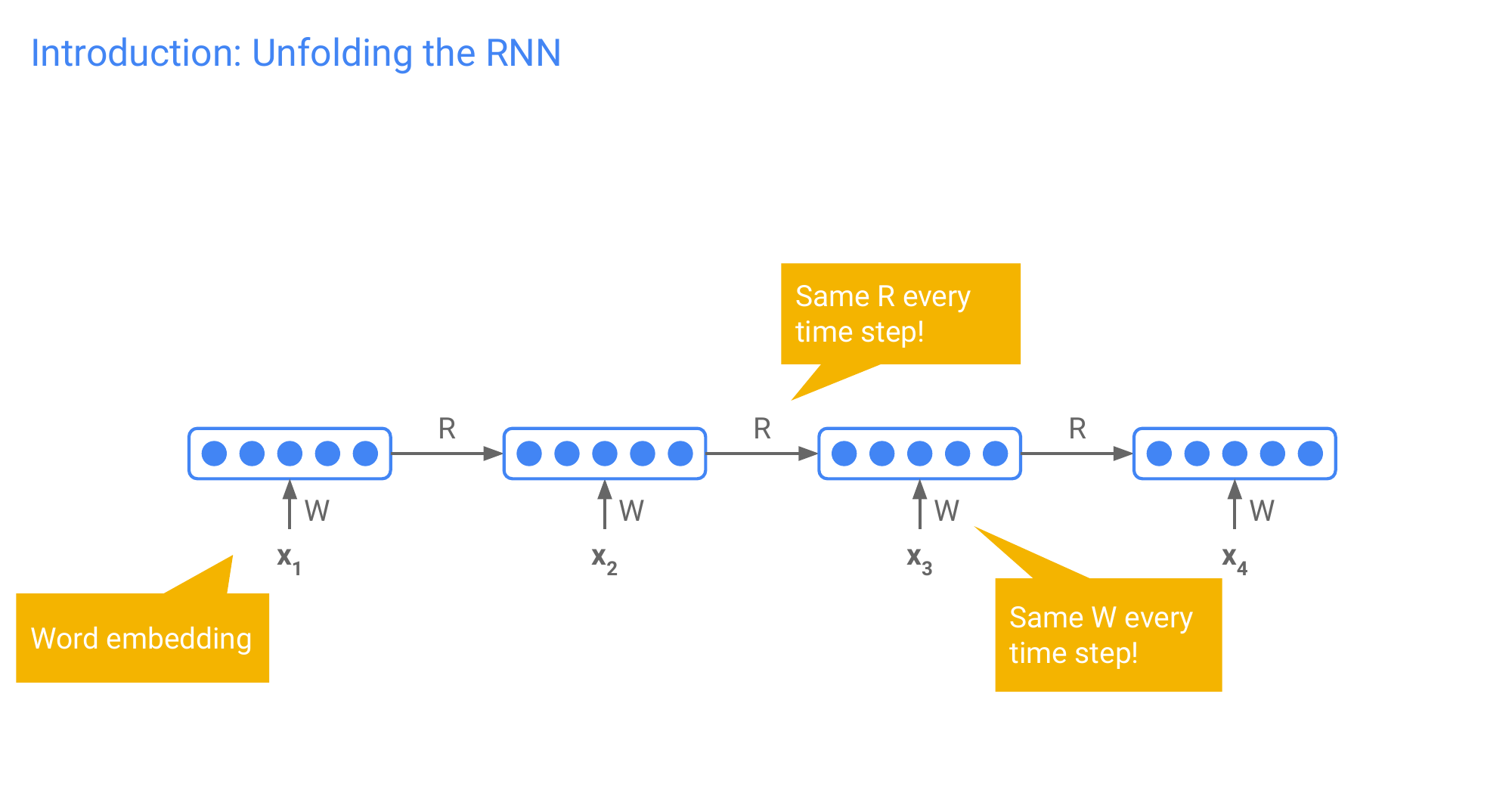
The W and the R amtrix are the same, they are shared
53 Introduction: Making a prediction
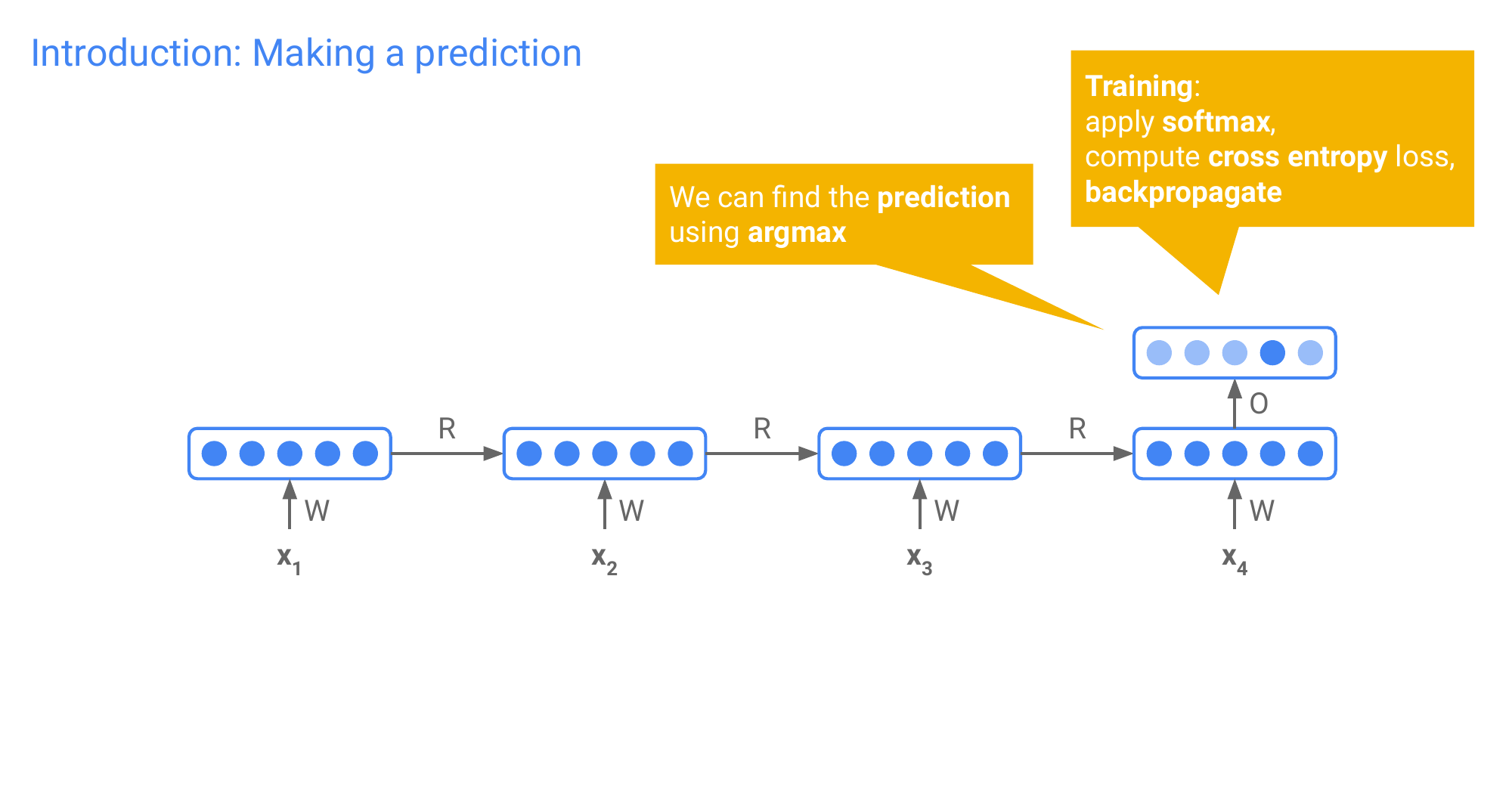
When you reach the end of the sentence, then you use the ouput vector for this word as the sentence representation. We can do this vecause this last time step was influenced by the entire history so that is why we substitute, this as our sentence representation. And then we can project it as 5 dimensional representation and then we take the argmax or softmax based on this representation
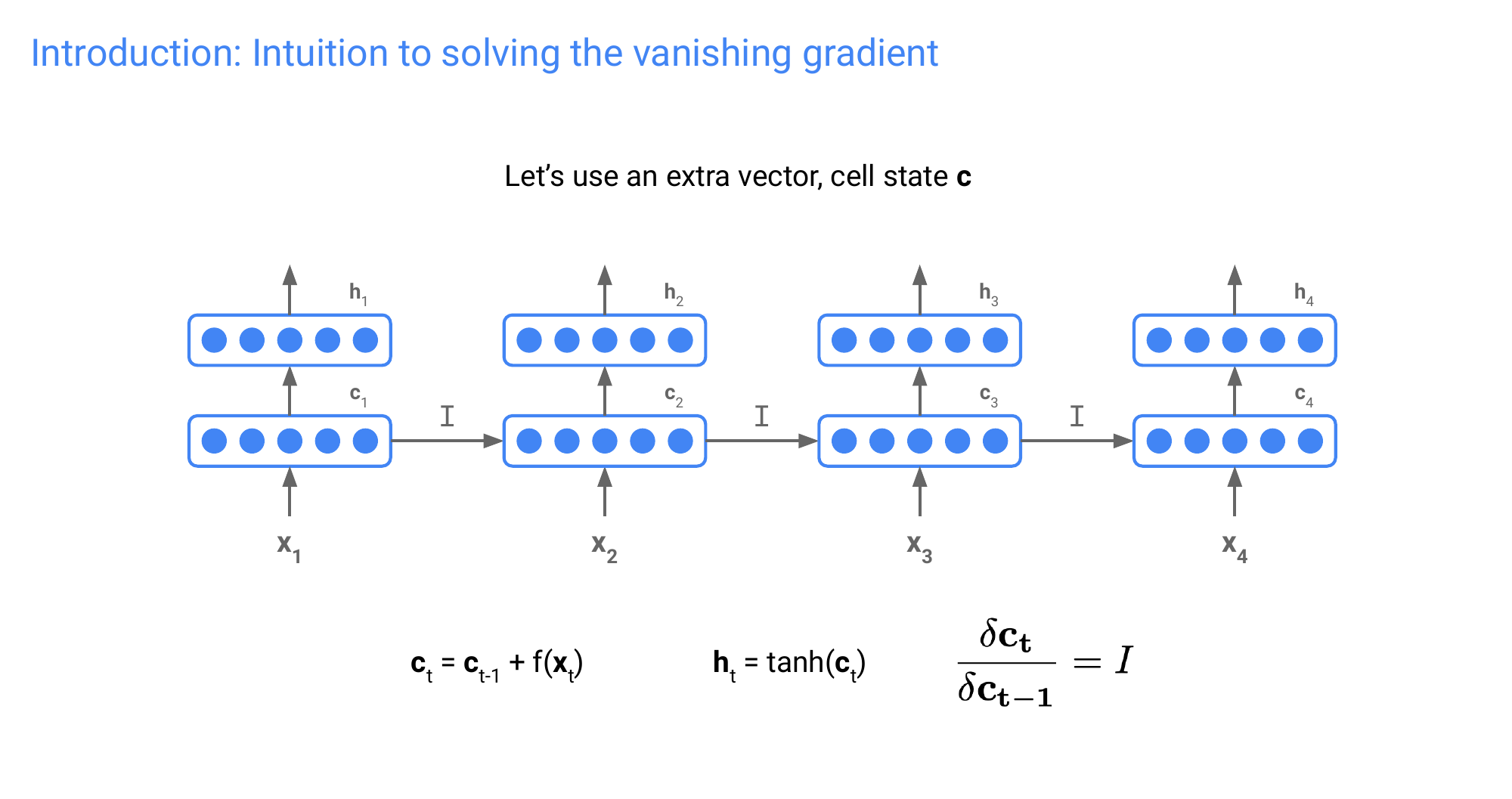
54 Introduction: The vanishing gradient problem
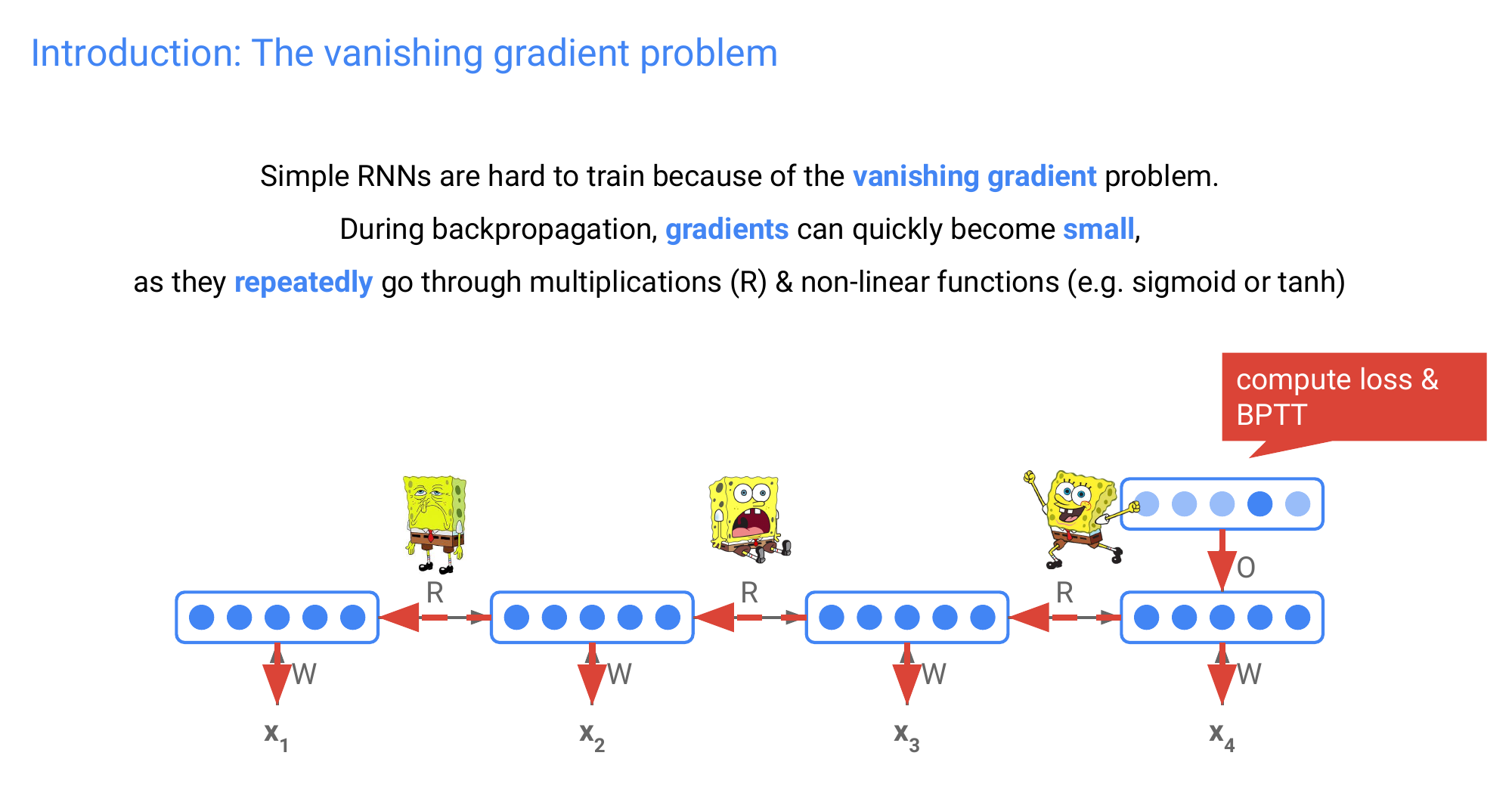
They tend to surfer from the vanishing problem
55 Introduction: The vanishing gradient problem
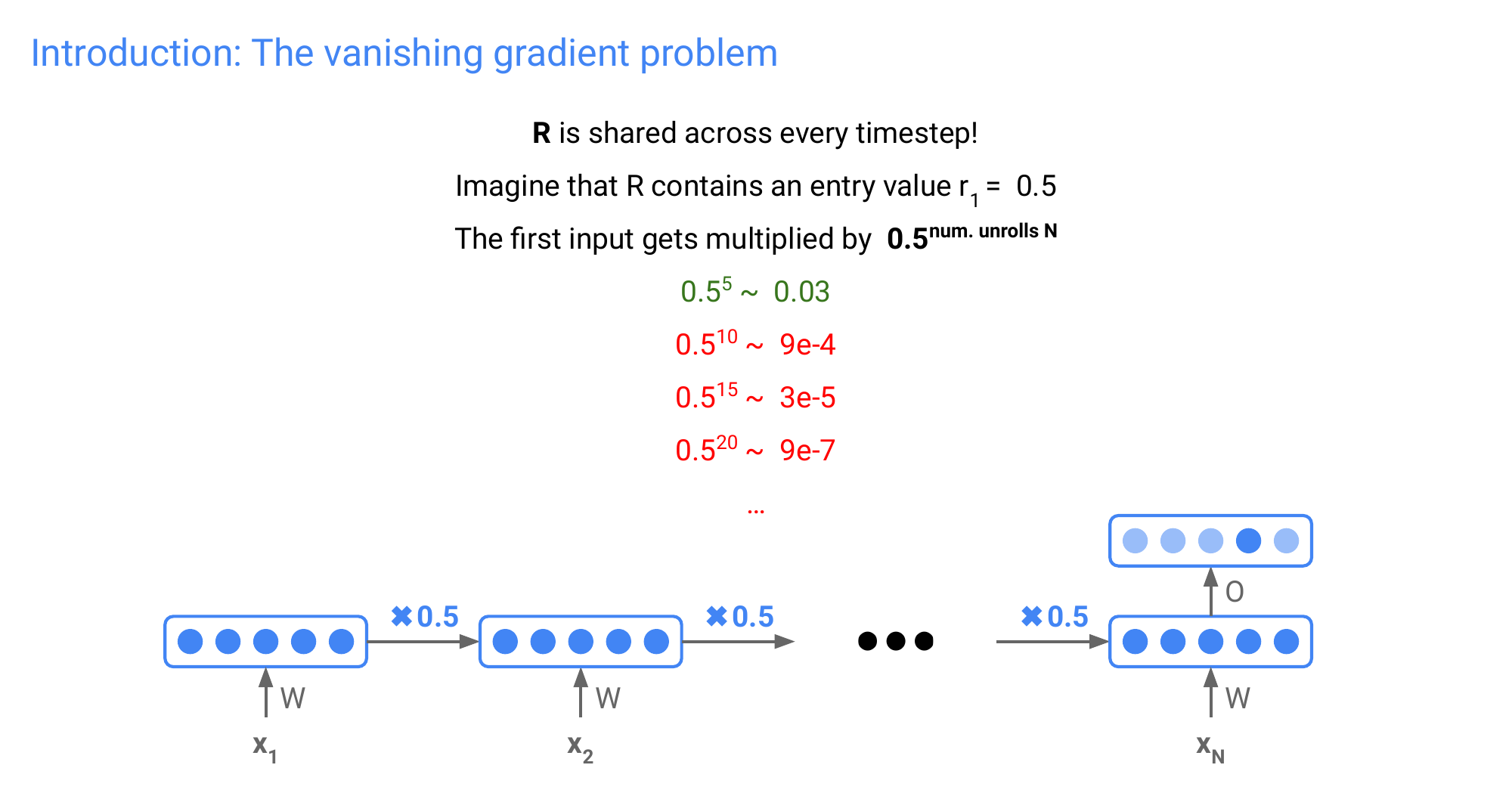
Here 5 num unrolls N refers to the amount of words you have in a sentence
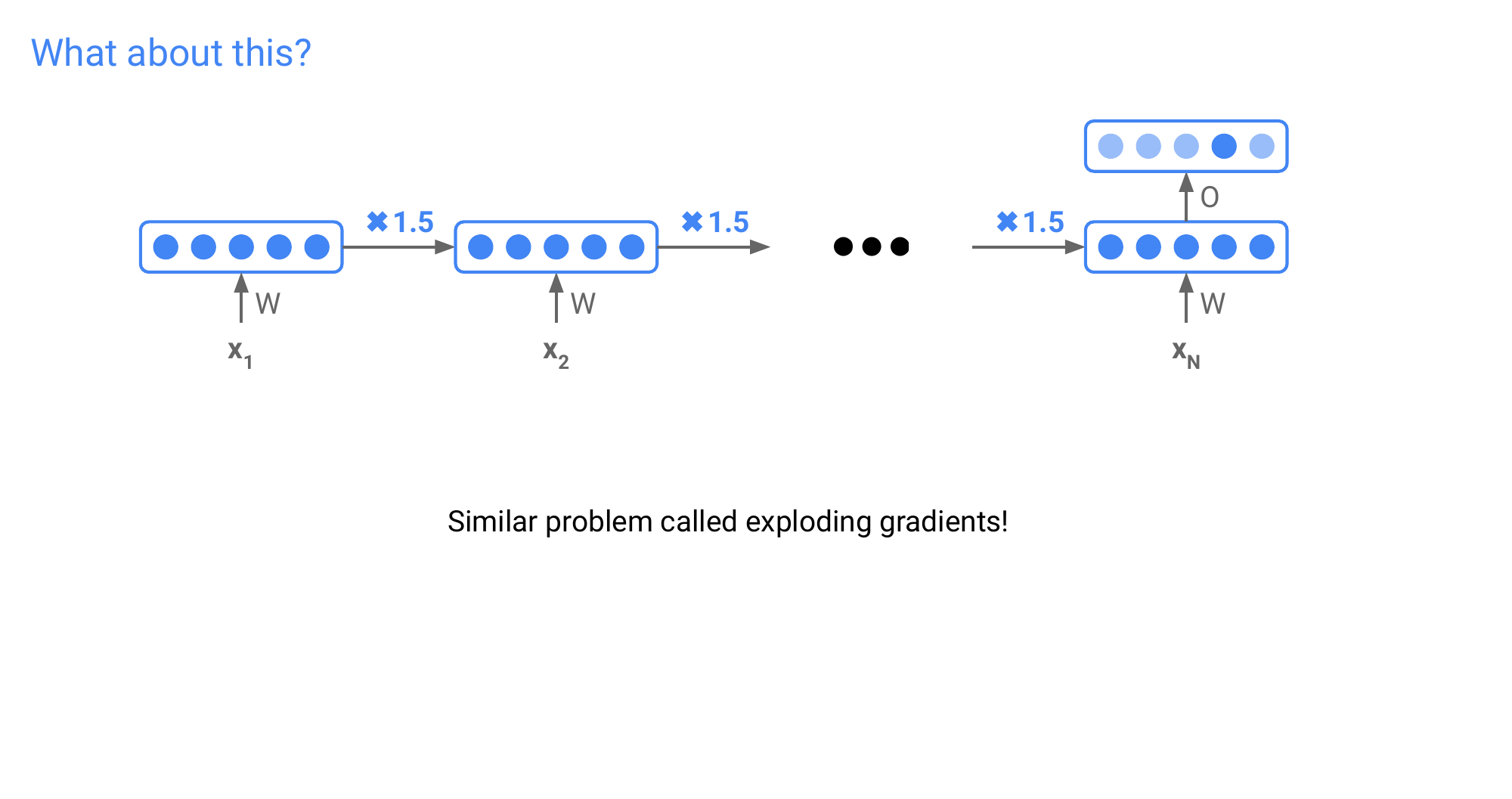
56 What about this?
57 RNN vs ANN
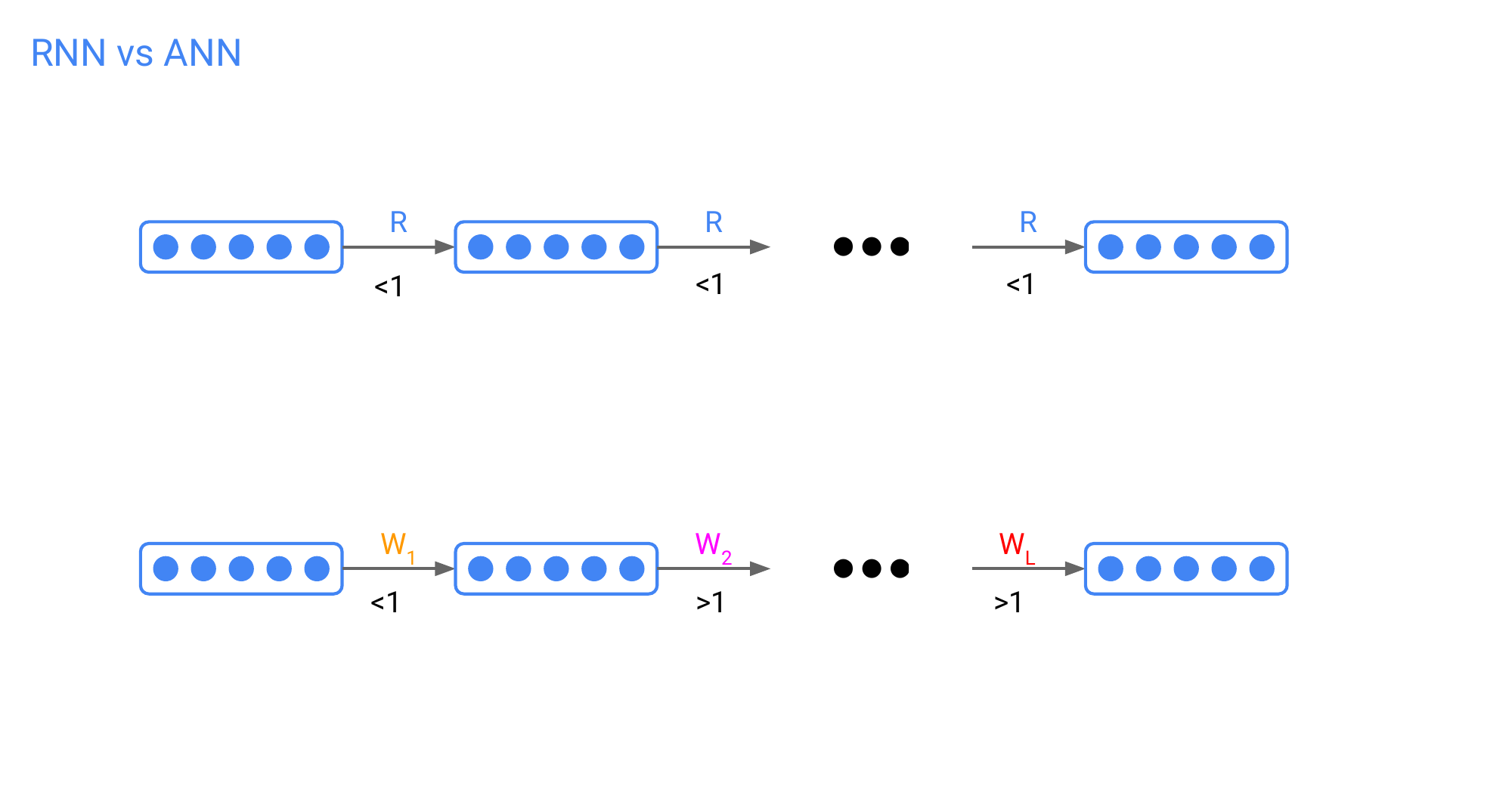
In the ANN you have different parameters for your matrix in each layer and the problem could cancel out. However even in ANN you can run into vanishing/exploding gradients

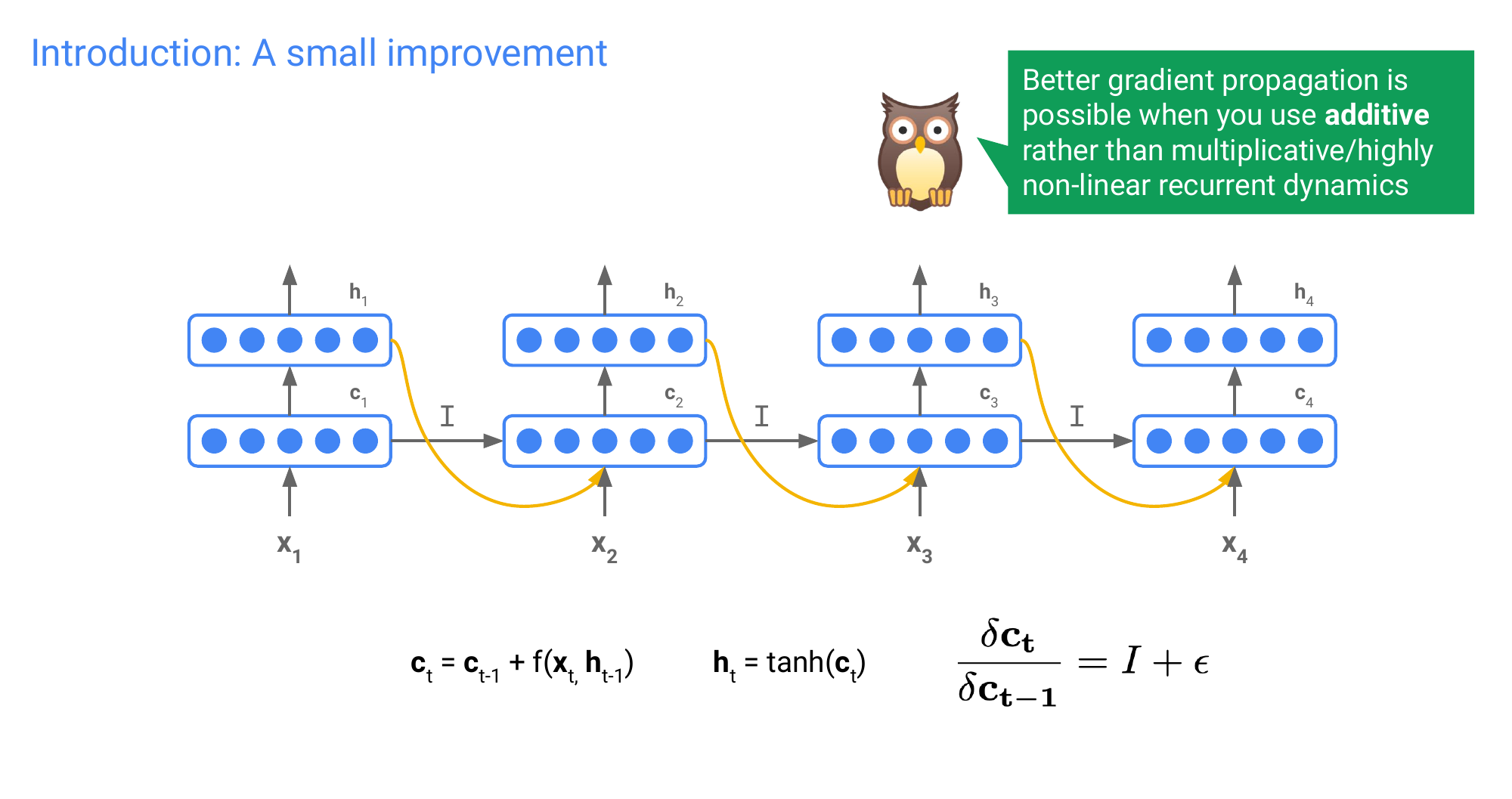
58 Long Short-Term Memory (LSTM)
CV: resNET skip connections to aliviate exploding/vanishing gradients
NLP: LSTM were introduced

LSTM are good to deal with long-term dependencies because they are able to cpe with exploding/vanishing gradients
59 LSTM: Core idea

The cells are supposed to capture the long term memory information from the sentence
This is good because backpropagation through time with have this partially uninterrupted gradient flow
60 LSTMs
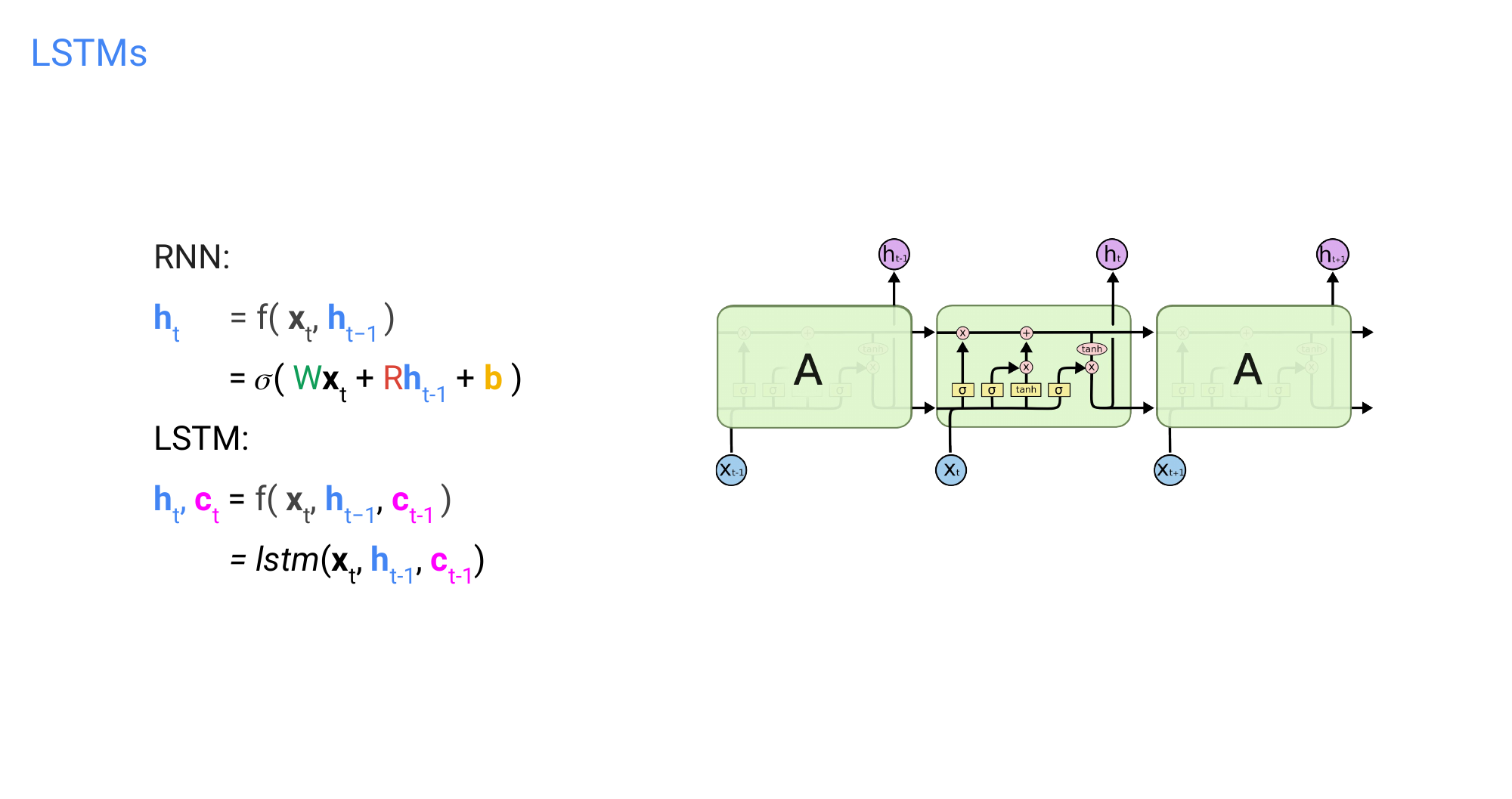
Now the activation function here would be the LSTM, so each copy would contain an LSTM cell where before we have one layer and now we will have the cell with four different layers interacting with each other
61 LSTM cell
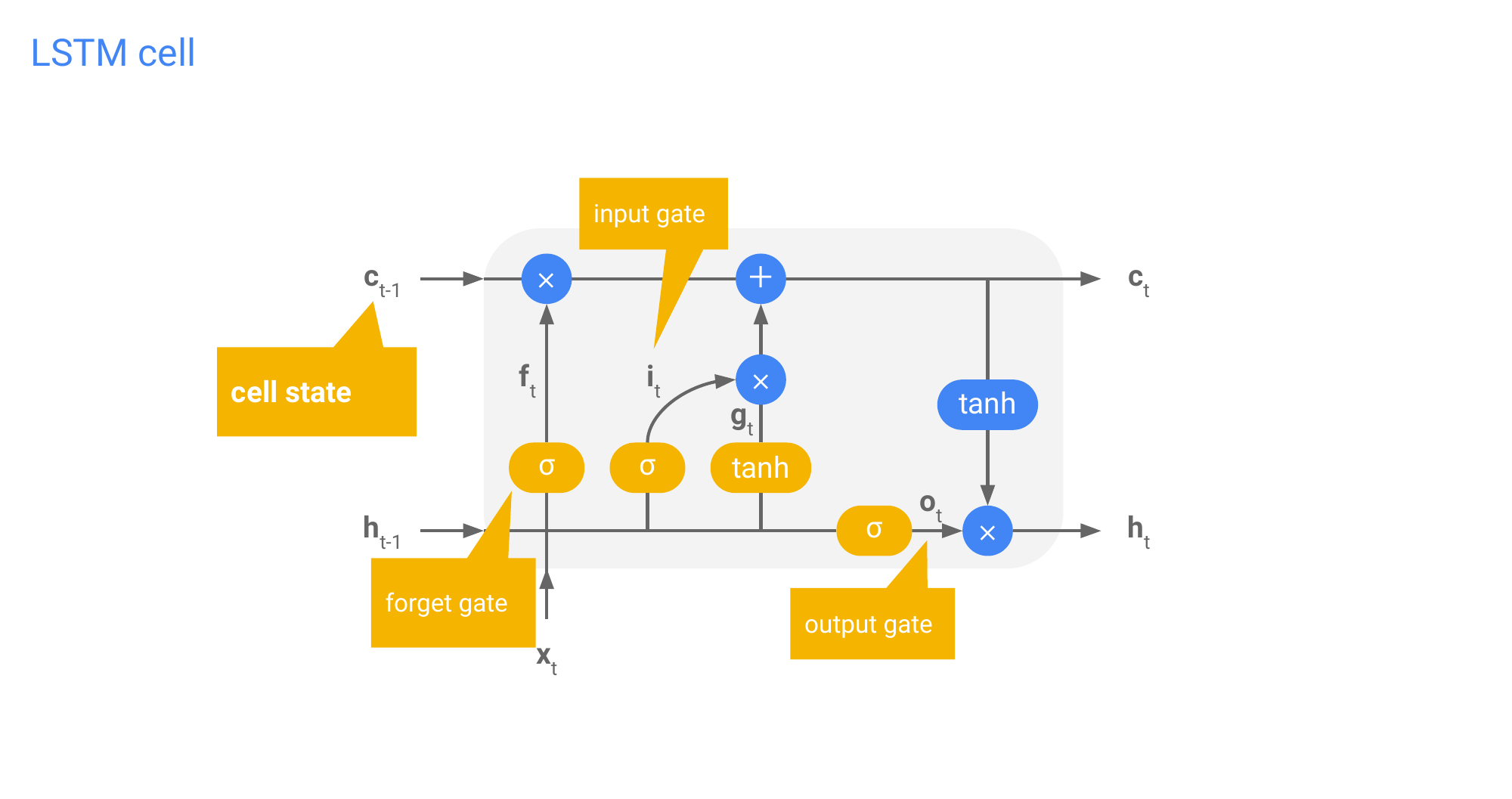
3 gates:
- forget gate
- input gate
- output gate
c_t is the memory cell, here we do not apply any weights, we just do multiplication and summation. This is why people call it as a conveyers belt. So here we forget information, we add information but information flows interrupted
62 LSTM: Cell state
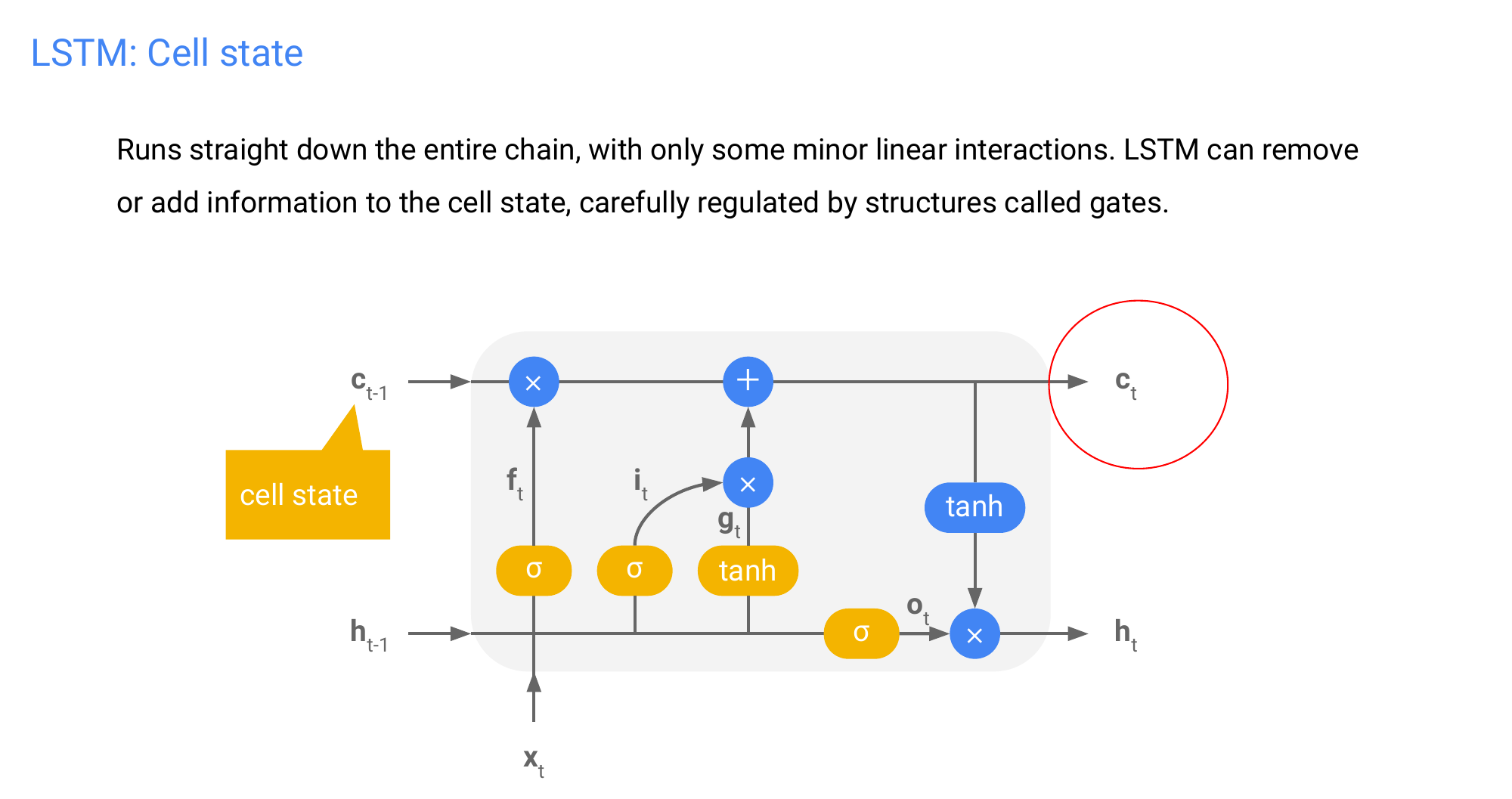
63 LSTM: Forget gate
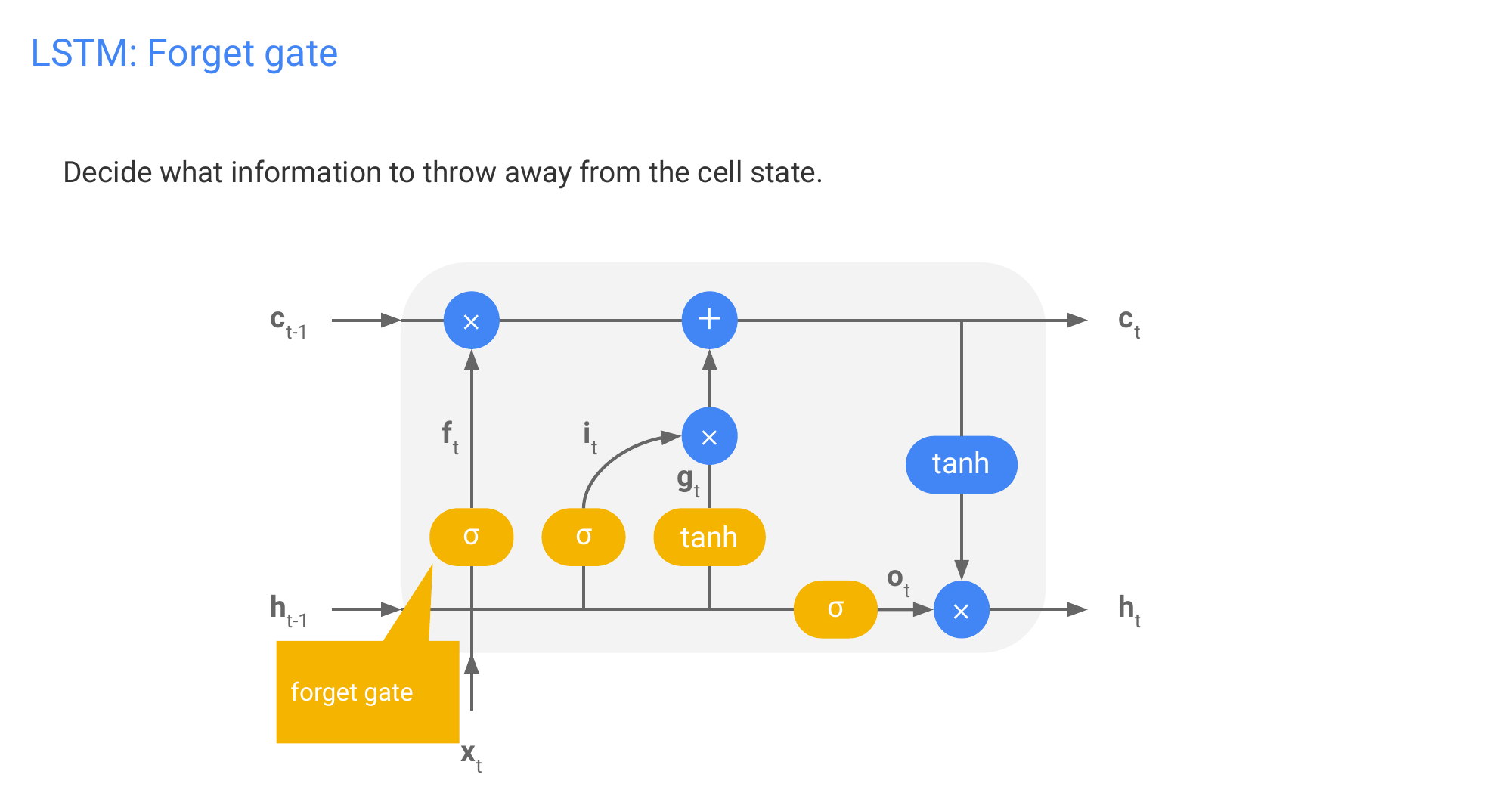
64 LSTM: Candidate cell
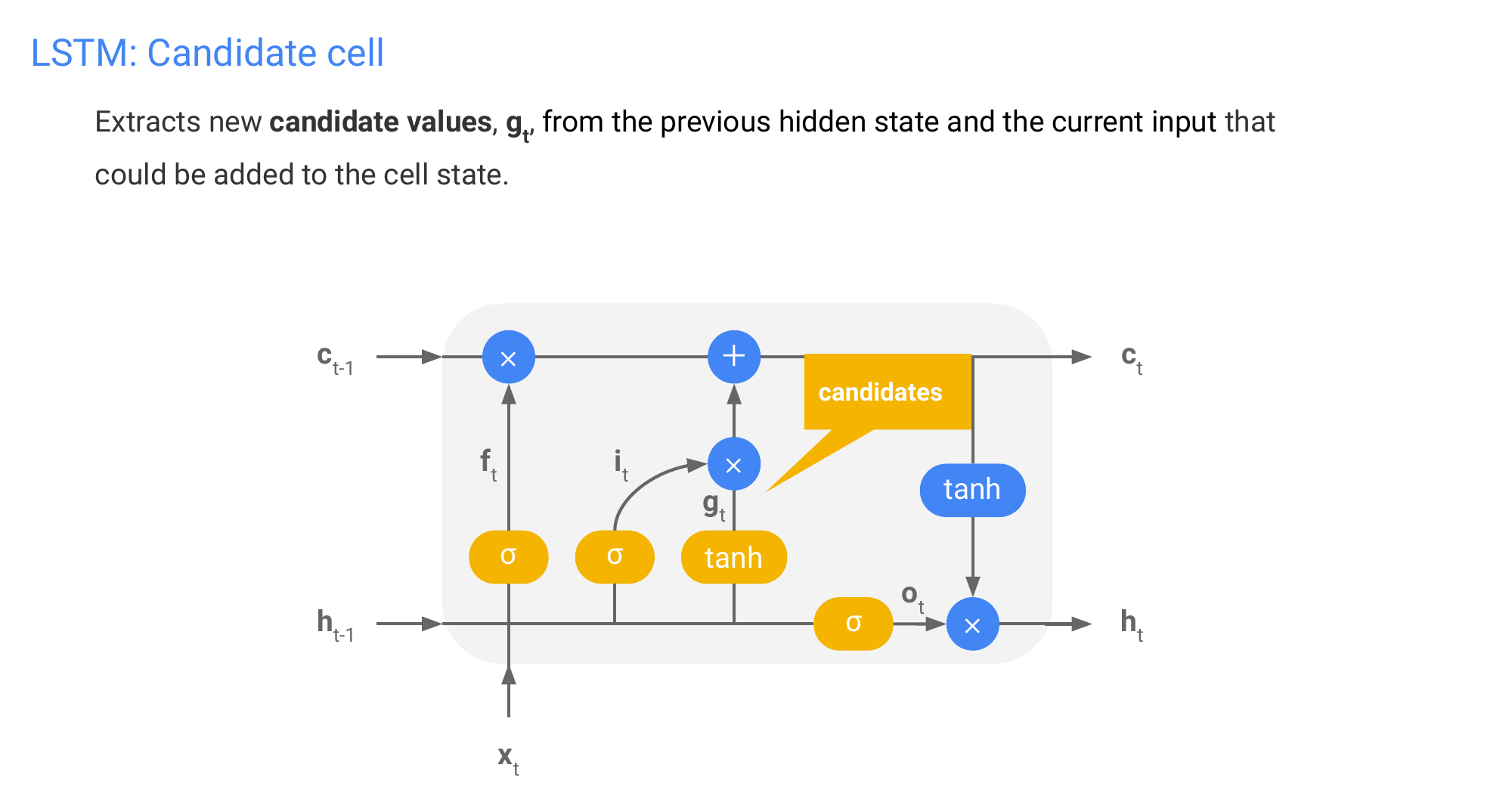
65 LSTM: Input gate
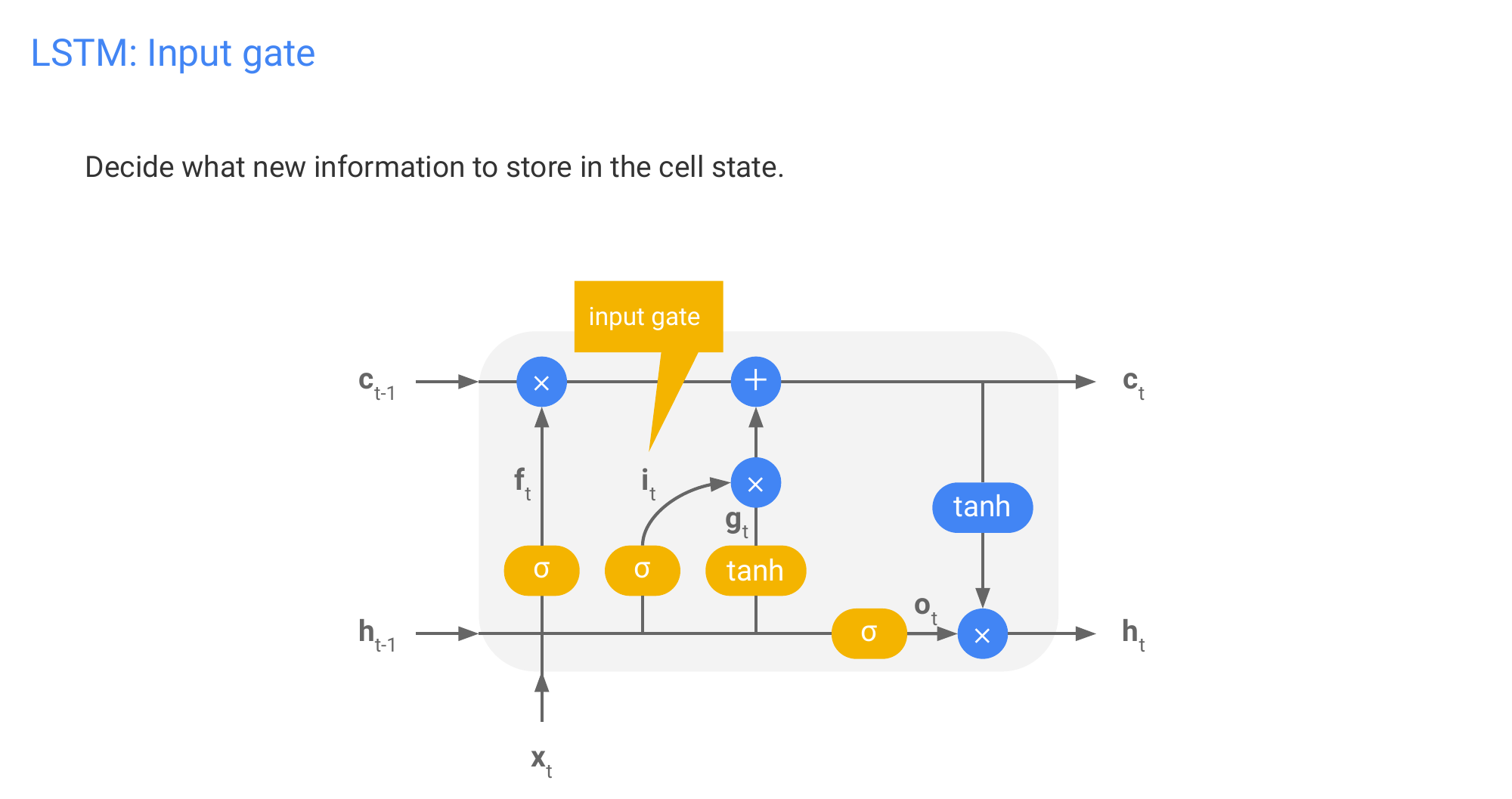
66 LSTM
67 LSTM: Output gate
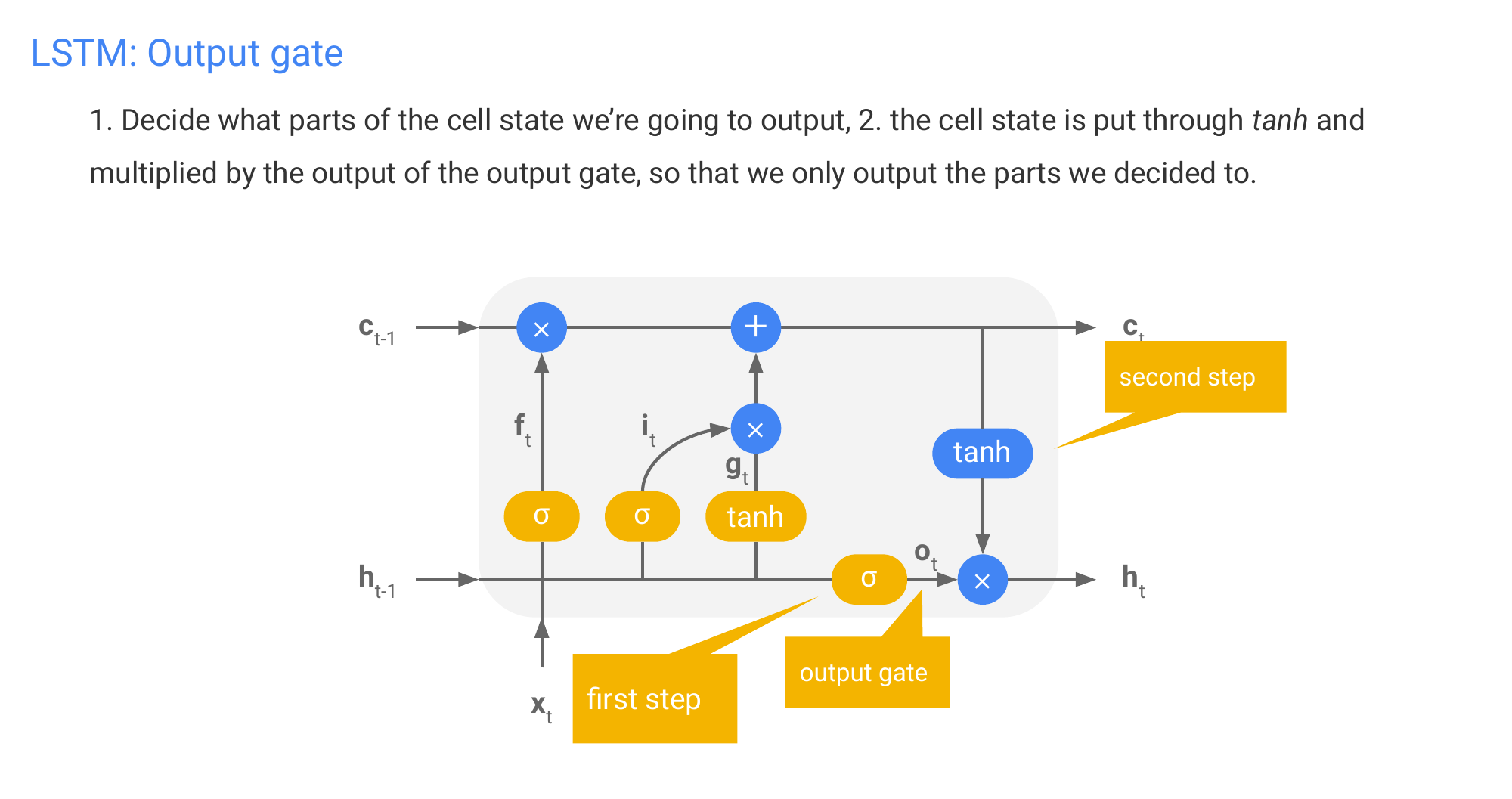
Here we are saying what do I want to keep from my long term memory. The ouput of that is going to be my new output vector.
67.1 Recap
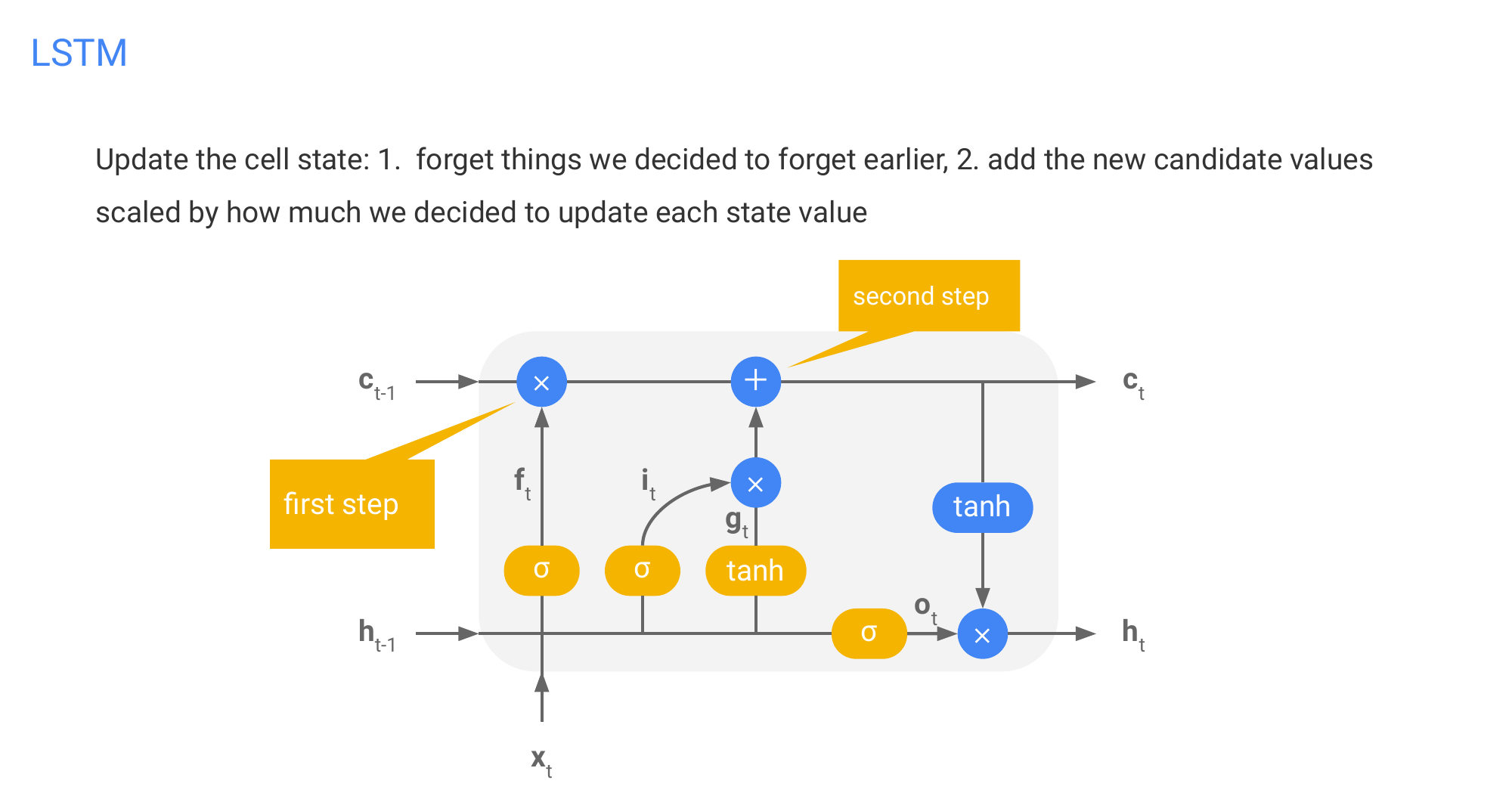
- Use the forget gate to get the input word x_t and the previous h_{t-1} with that you do apply softmax which then you multiply to the cell state which is the memory.
Here if you multiply by 1, then you wan to keep those items in memory. If 0 then you do not want to conserve them.
We use the candidate gate where you mutliply the ouput of the tanh which gives candidate values between -1 and 1 with some scaled softmax from the input gate. With this we selectively add what to conserve in the memory cell
We update the values of the ouput gate which we take: from the cell memory values between -1 to 1 and we multiply these by a softmax version from the input words x_t and also the previous state h_{t-1}
- Step 1 & 2 is called long-term memory
- Step 3, is the short term memory. This is a filtered version of the long-term memory.
68 Long Short-Term Memory (LSTM)

- Cell state is the long term memory
- Hidden state is your short term memory
69 LSTMs: Applications & Success in NLP


70 Summary fo models seen so far

Sequence models :
- RNN
- LSTM
Tree-structure models are the ones that are also sensitive to the syntactic structure
71 Second approach: Sentence + Sentiment + Syntax
72 Exploiting tree structure

Compositionality was this idea that you cannot derive the meaning of sentences from the meaning of the individual words.
In the models seen so far, we were getting the sentence representation deriving it from the individual words. But we were not taken the syntactic structure into account. These Tree LSTM allow us to do both. So we will get the meaning of the words and also the rules that combine them
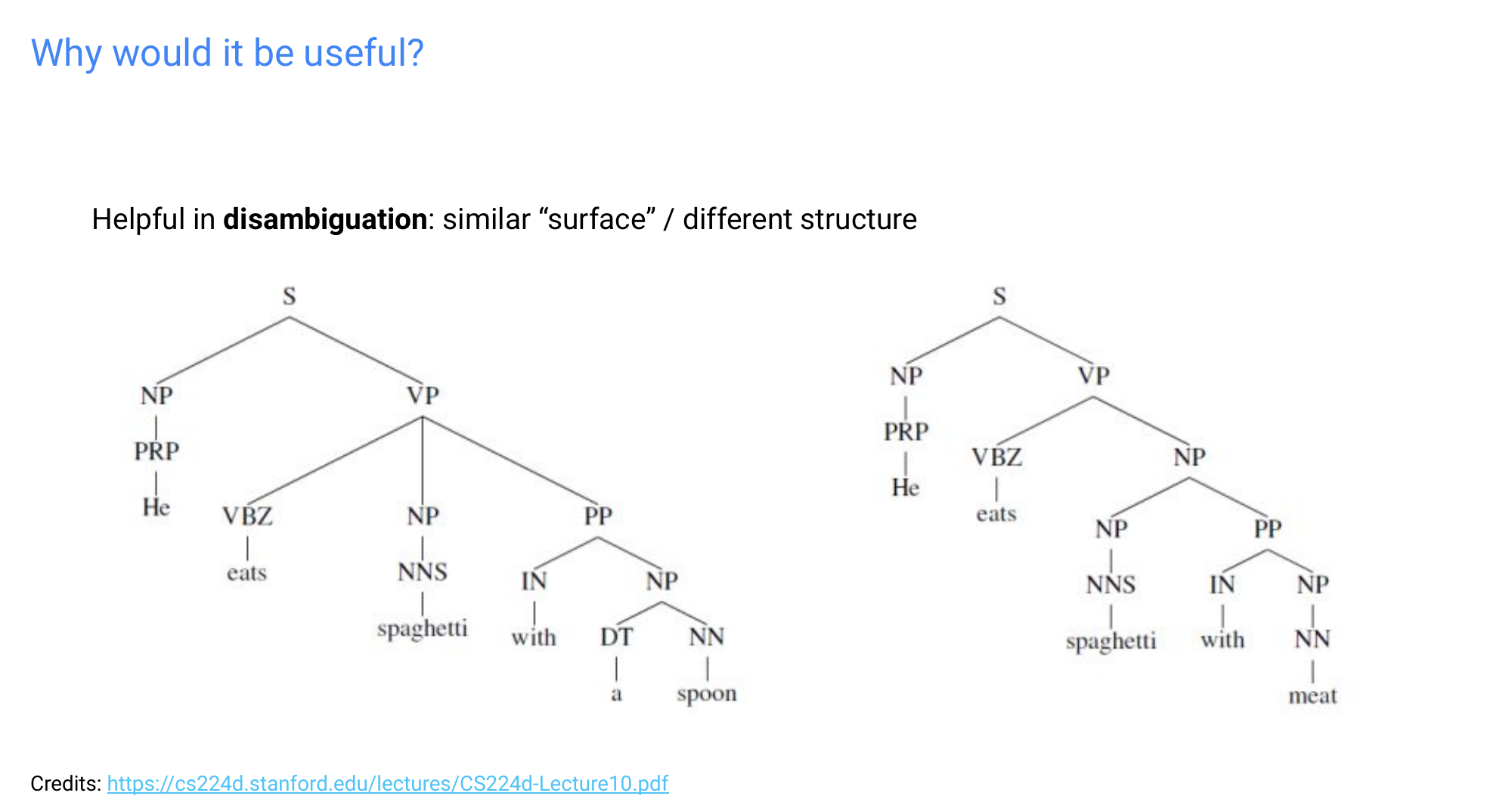
73 Why would it be useful?
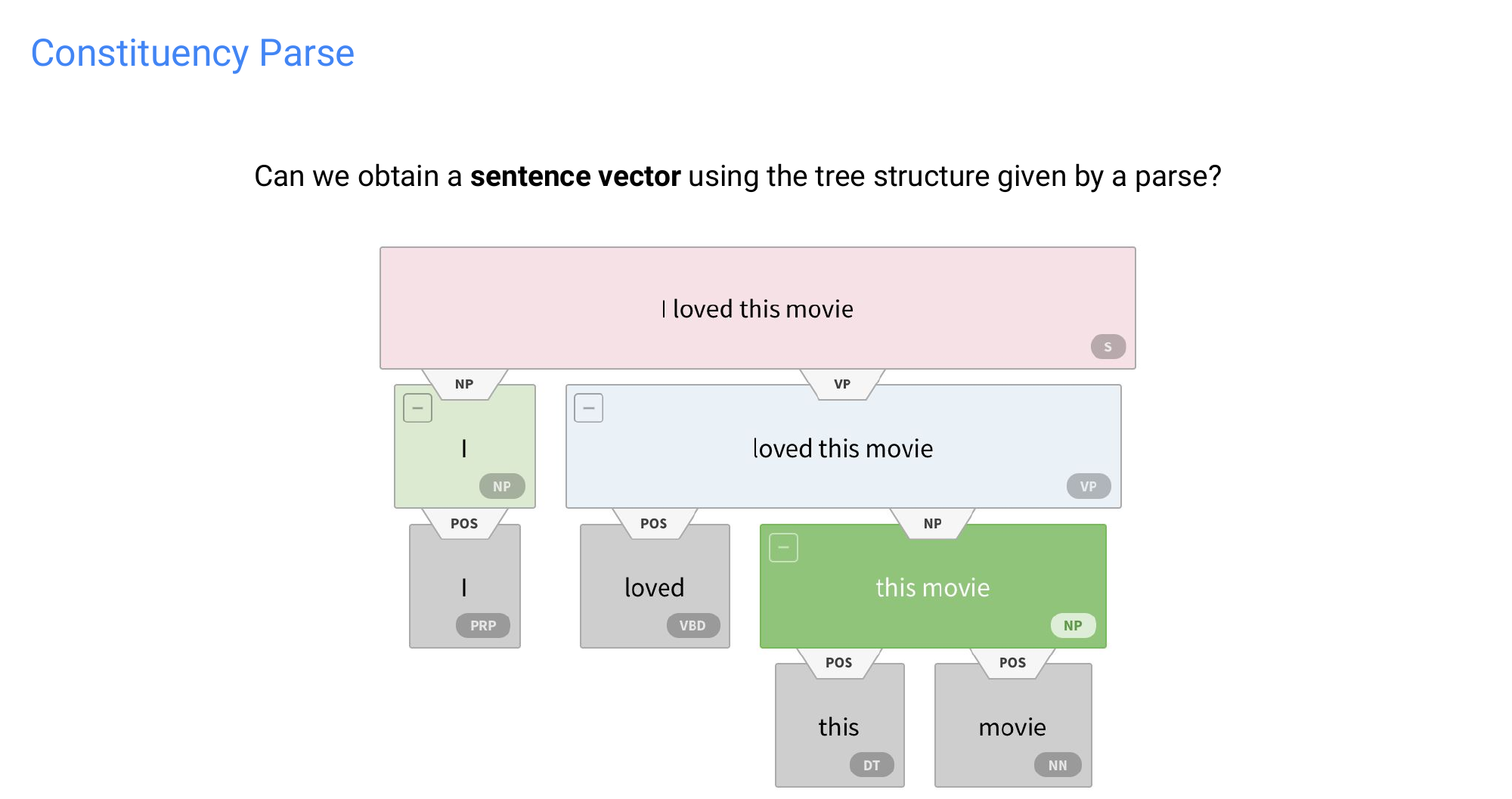
74 Constituency Parse
75 Recurrent vs Tree Recursive NN
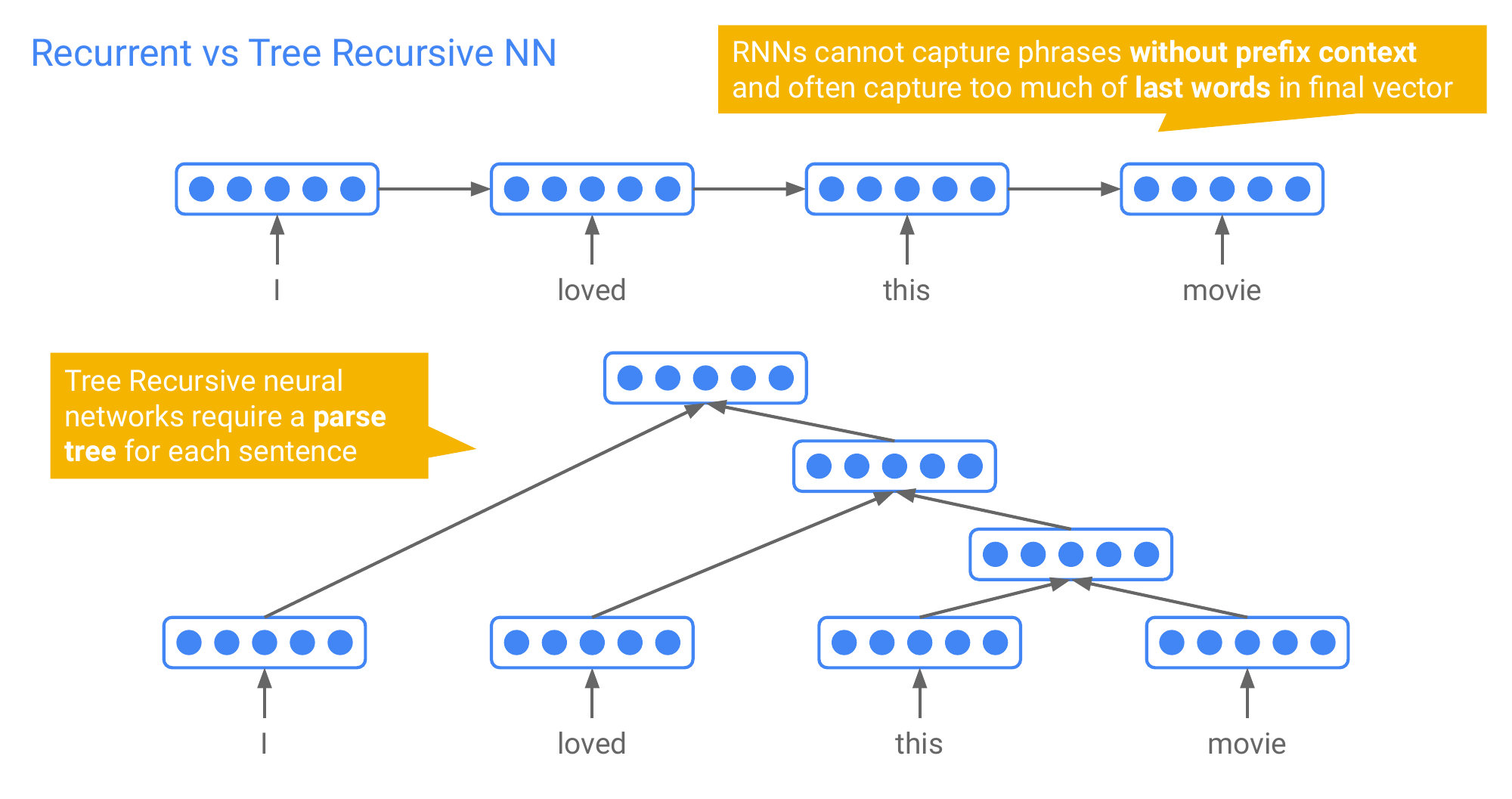
Recurrent NNS that are LSTMs but you also have tree RNN which are recursive
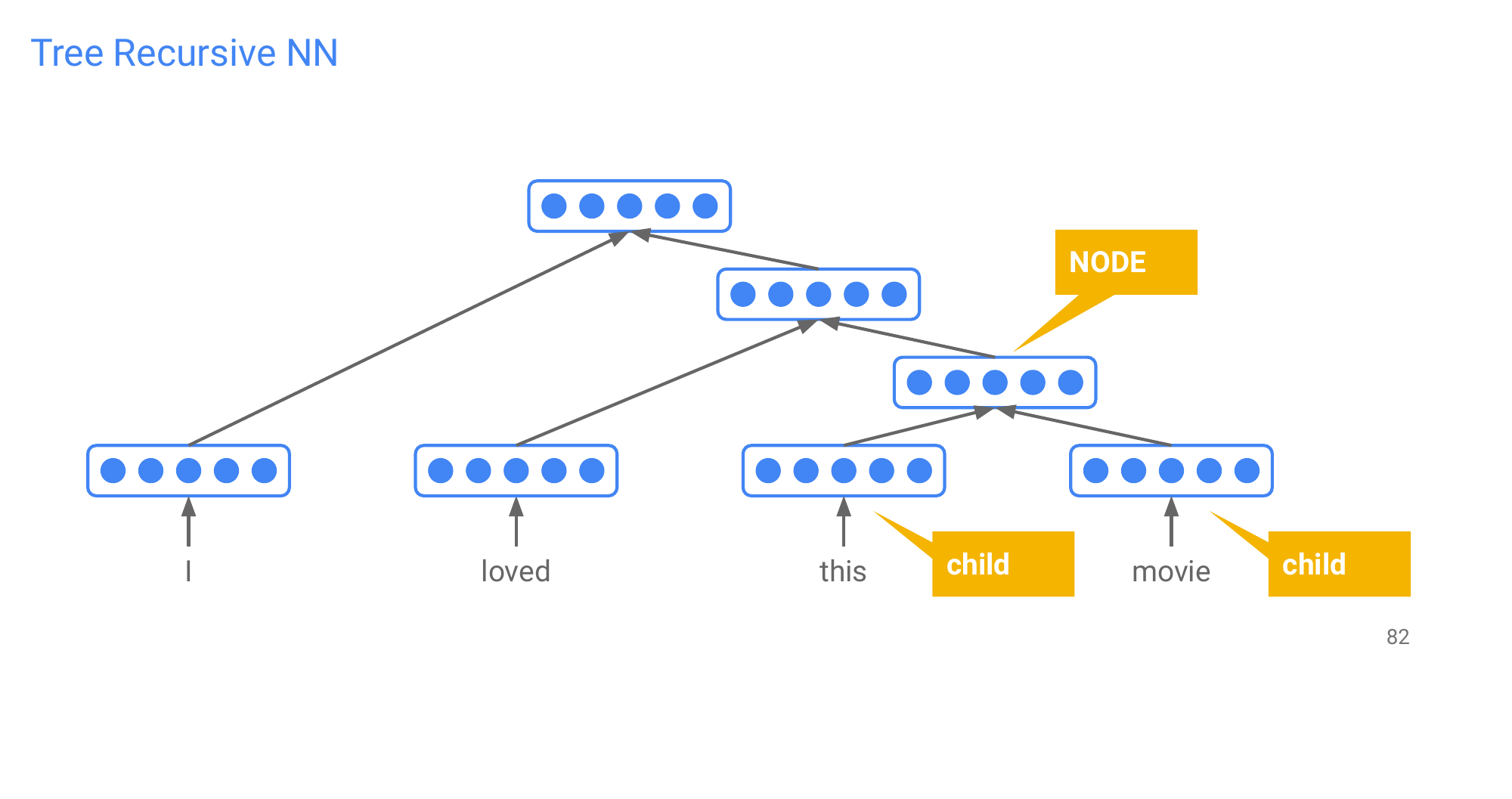
If you input “I loved this movie” to the RNN you will not be able to model, the phrase independetly of the previous words in the sentence. So for instance “this movie” is dependent of having seen “I Loved” that means I cannot extract separate phrase representations from your sentence representations
This is different in the three recursive NN, because you explicitly first compose “this movie” into a phrase representation and then you would make it dependent on the previous word while you go up in the three
76 Tree Recursive NN
77 Practical II data set: Stanford Sentiment Treebank (SST)
78 Tree LSTMs: Generalize LSTM to tree structure

We can input multiple children in each time step
79 Tree LSTMs

You can use any number of children that you want but you will loose child order information
N-ary Tree LSTM: in practical Binary parse tree
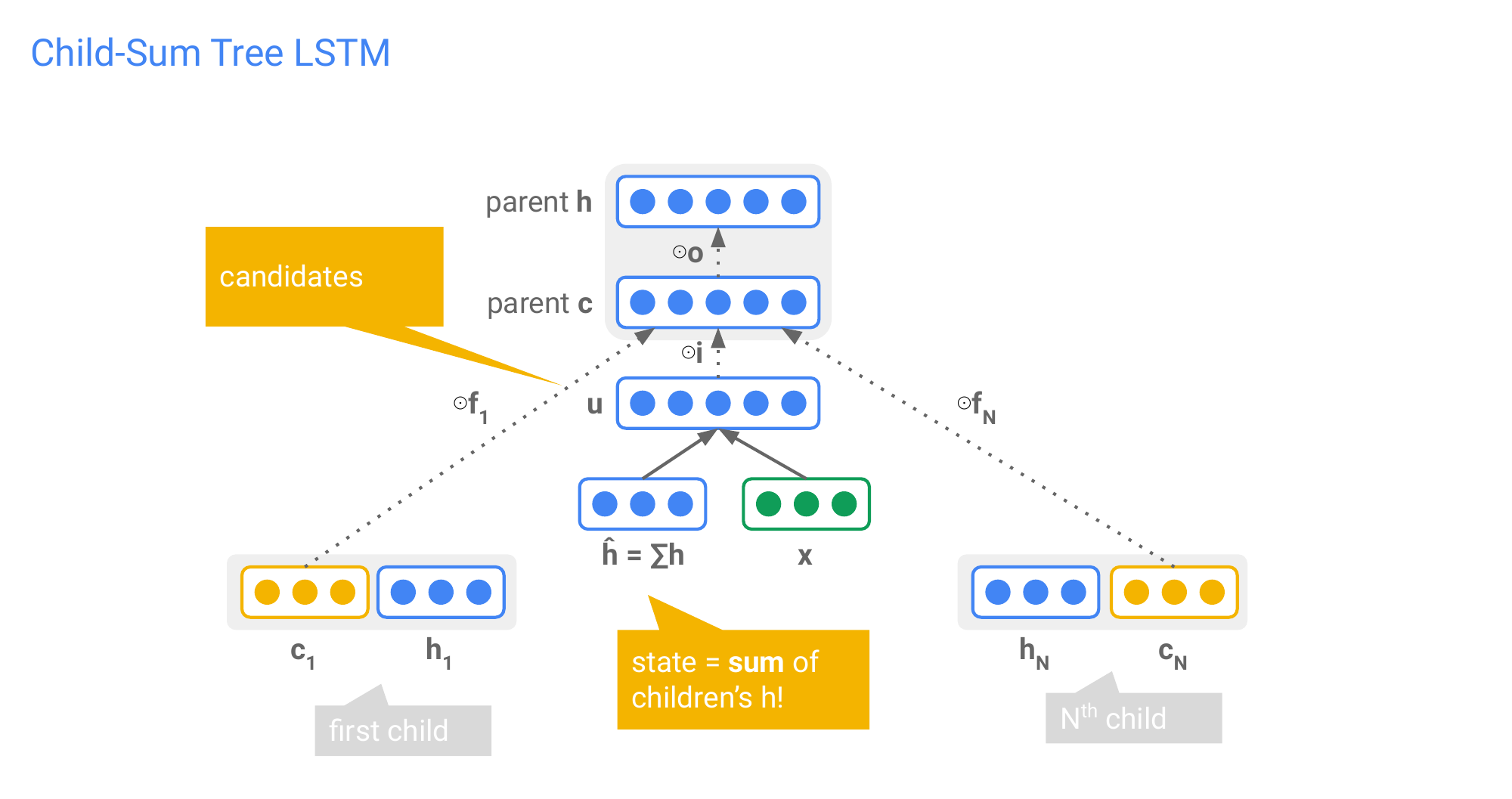
80 Child-Sum Tree LSTM

81 Child-Sum Tree LSTM
82 N-ary Tree LSTM

That means I have to input separatly to the model because they have separate parameters matrices, so you not just summed them up.
83 N-ary Tree LSTM
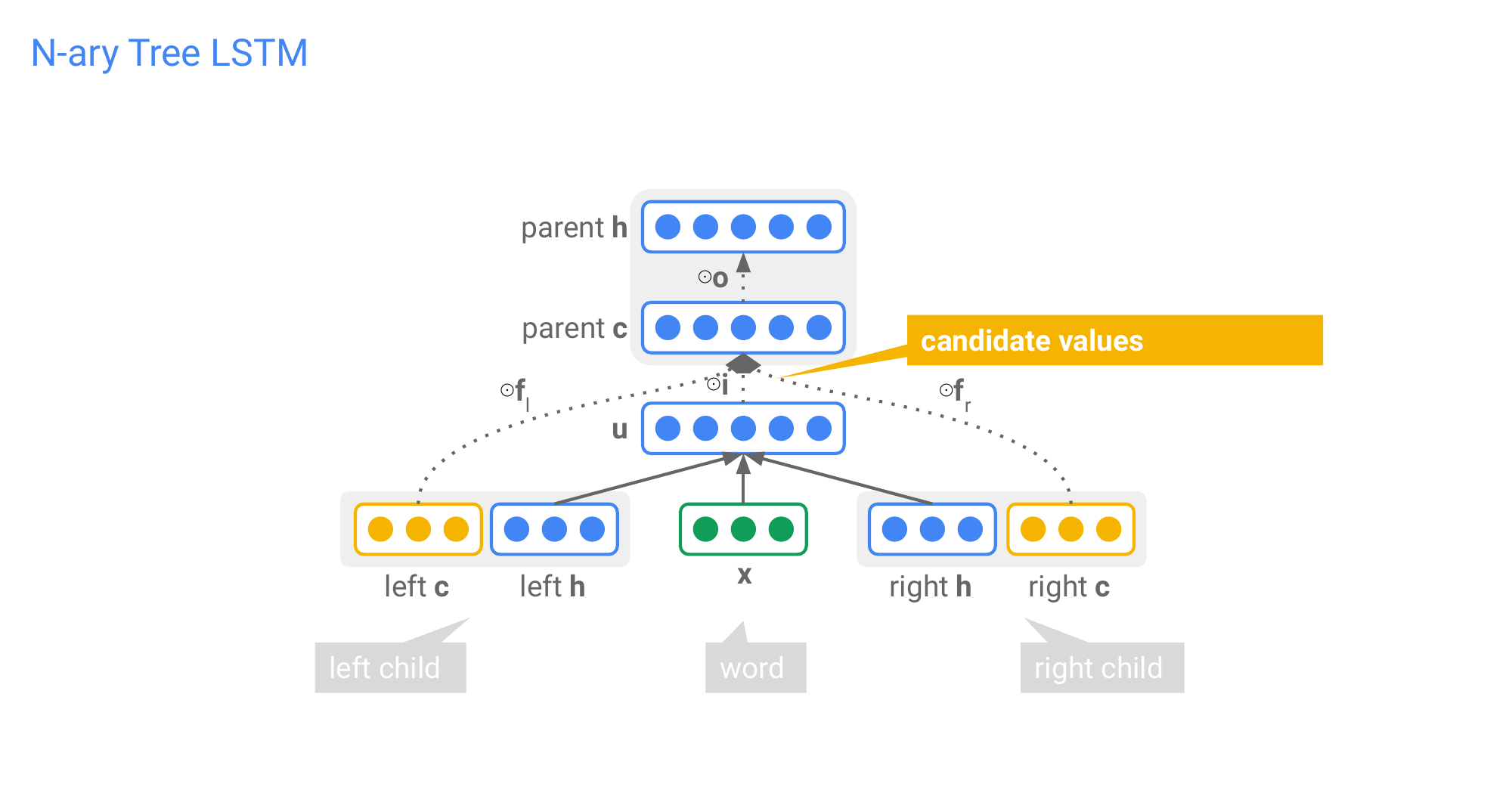
84 N-ary Tree LSTM

\(u_j\) is for the candidate gate
For each child \(h_j\), we have a separate parameter matrix and you ill be summing
85 LSTMs vs Tree-LSTMs

Tree-LSTM general, general LSTM its just a Tree-LSTM with one child. So if you have one child then you have your standard tree LSTM
86 Title

87 Title

88 Building a tree with a transition sequence
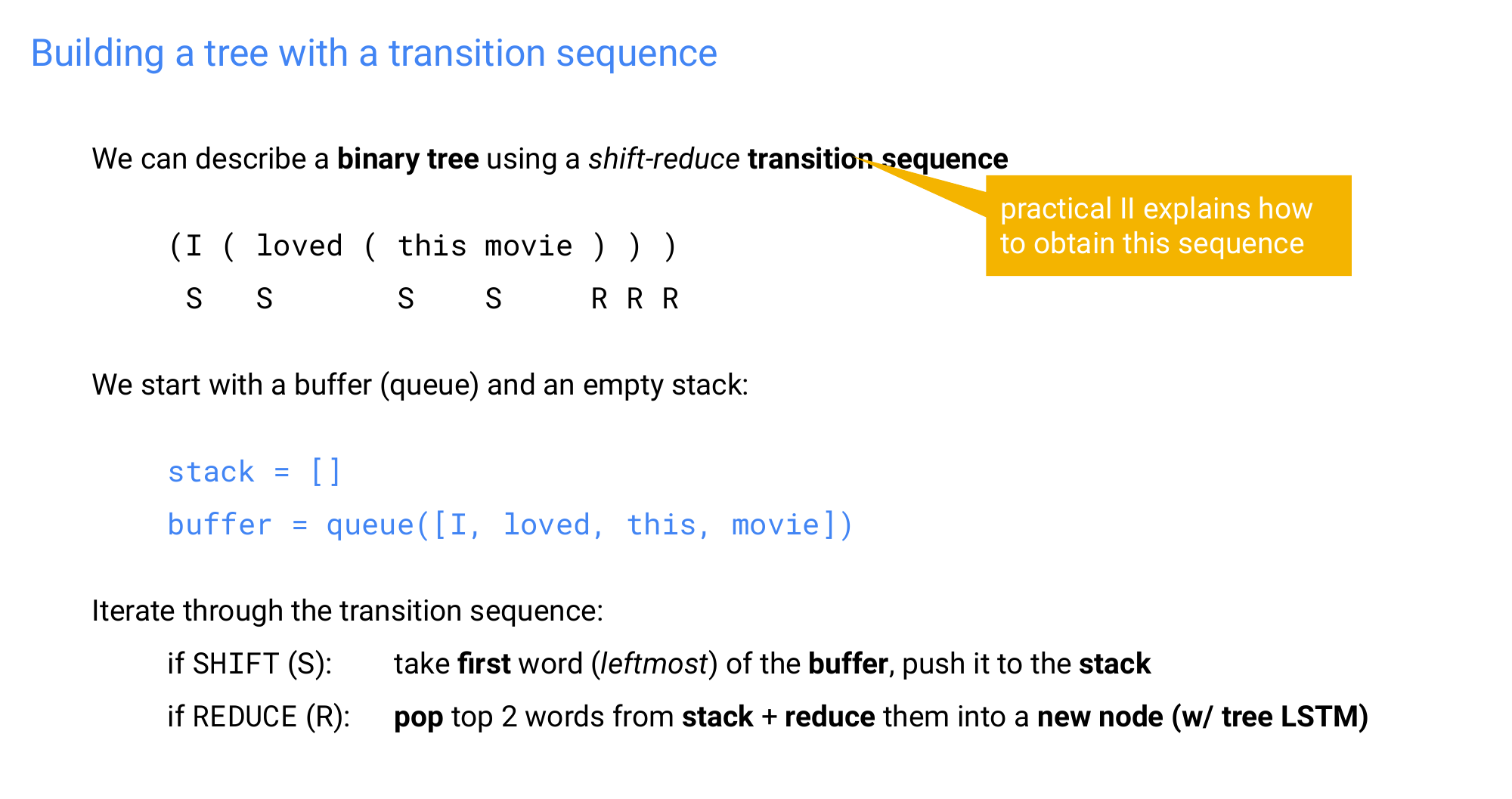
89 Transition sequence example

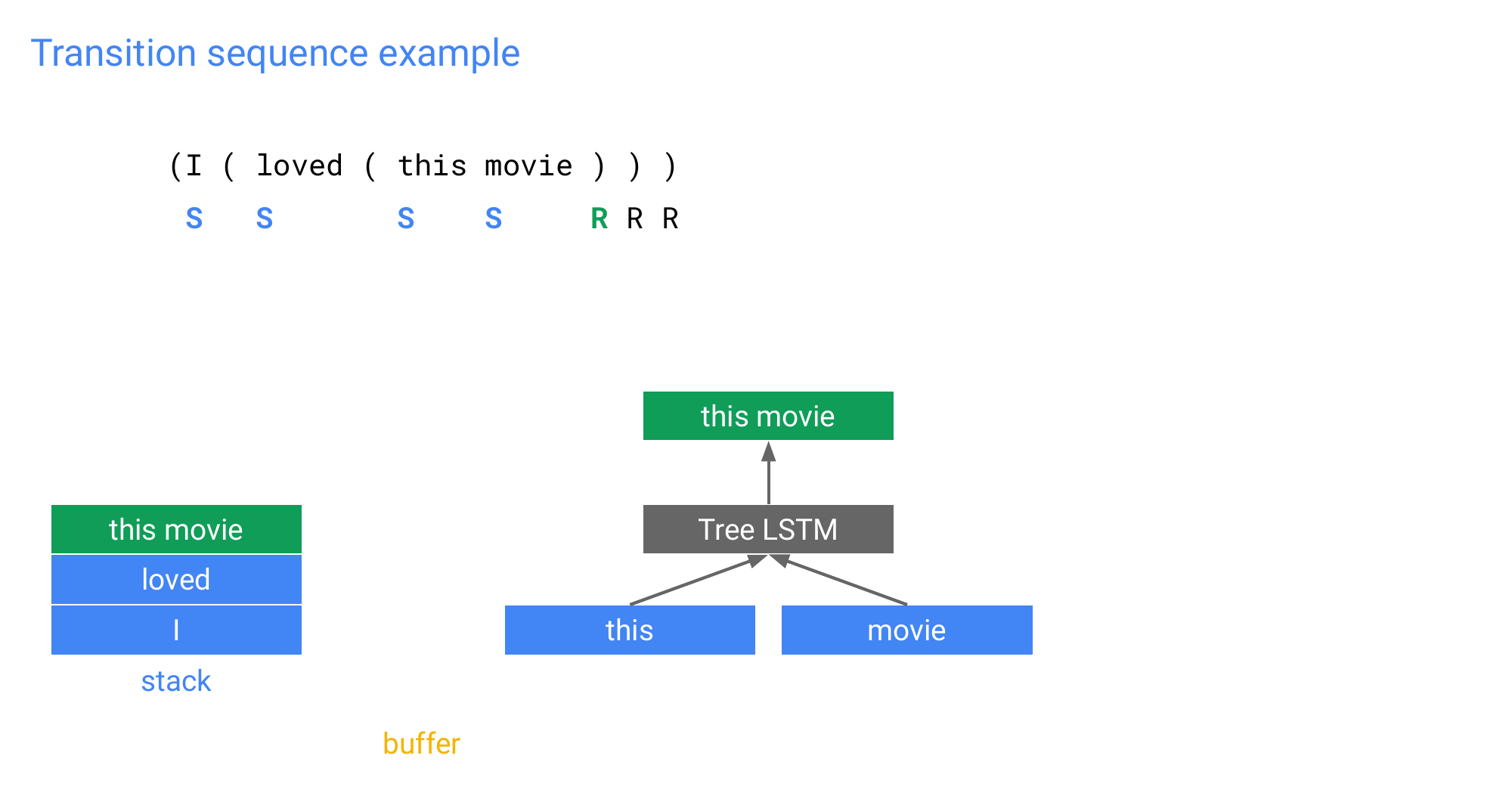
90 Transition sequence example

91 Transition sequence example

92 Transition sequence example

93 Transition sequence example

94 Transition sequence example
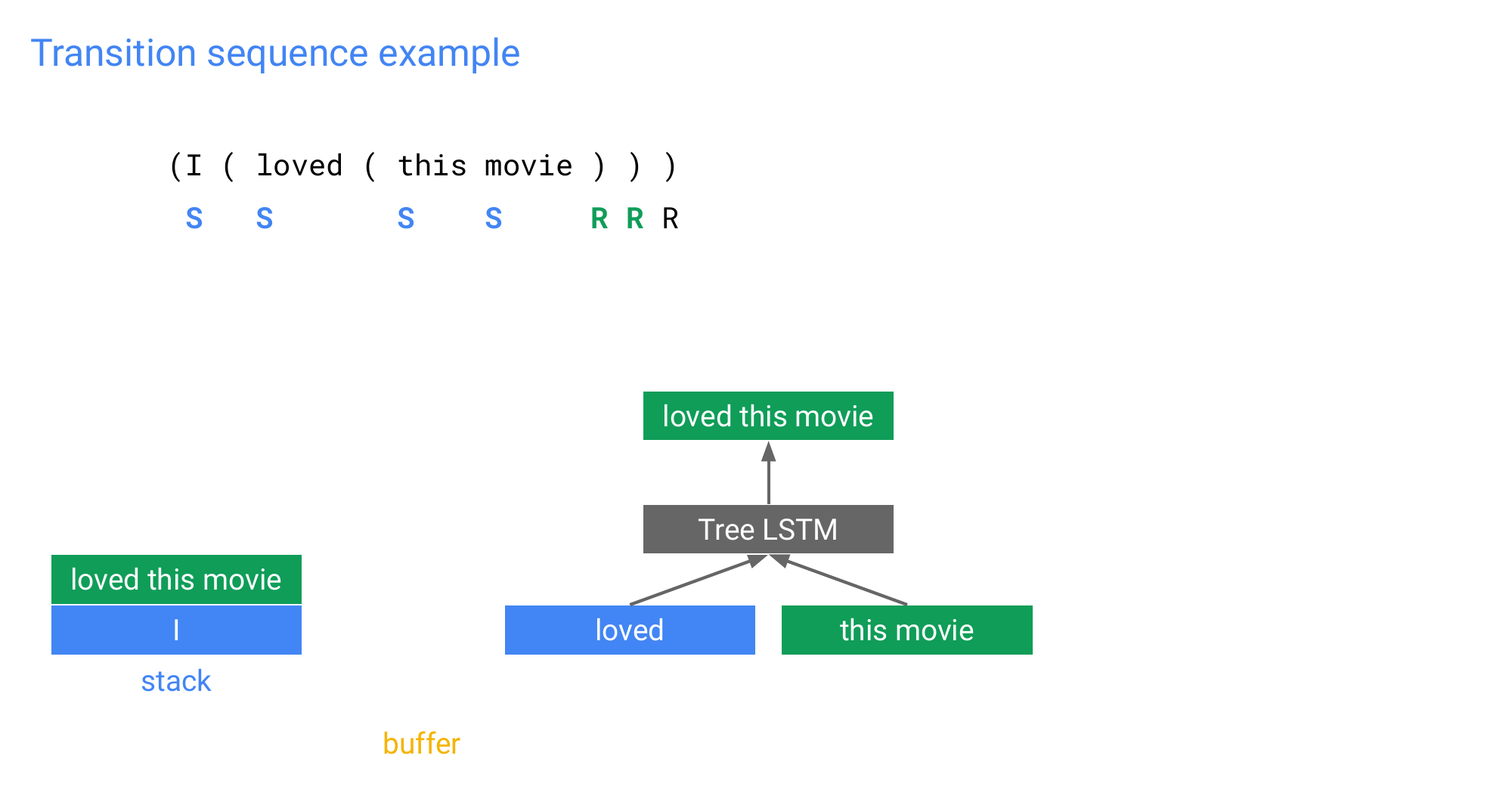
95 Transition sequence example
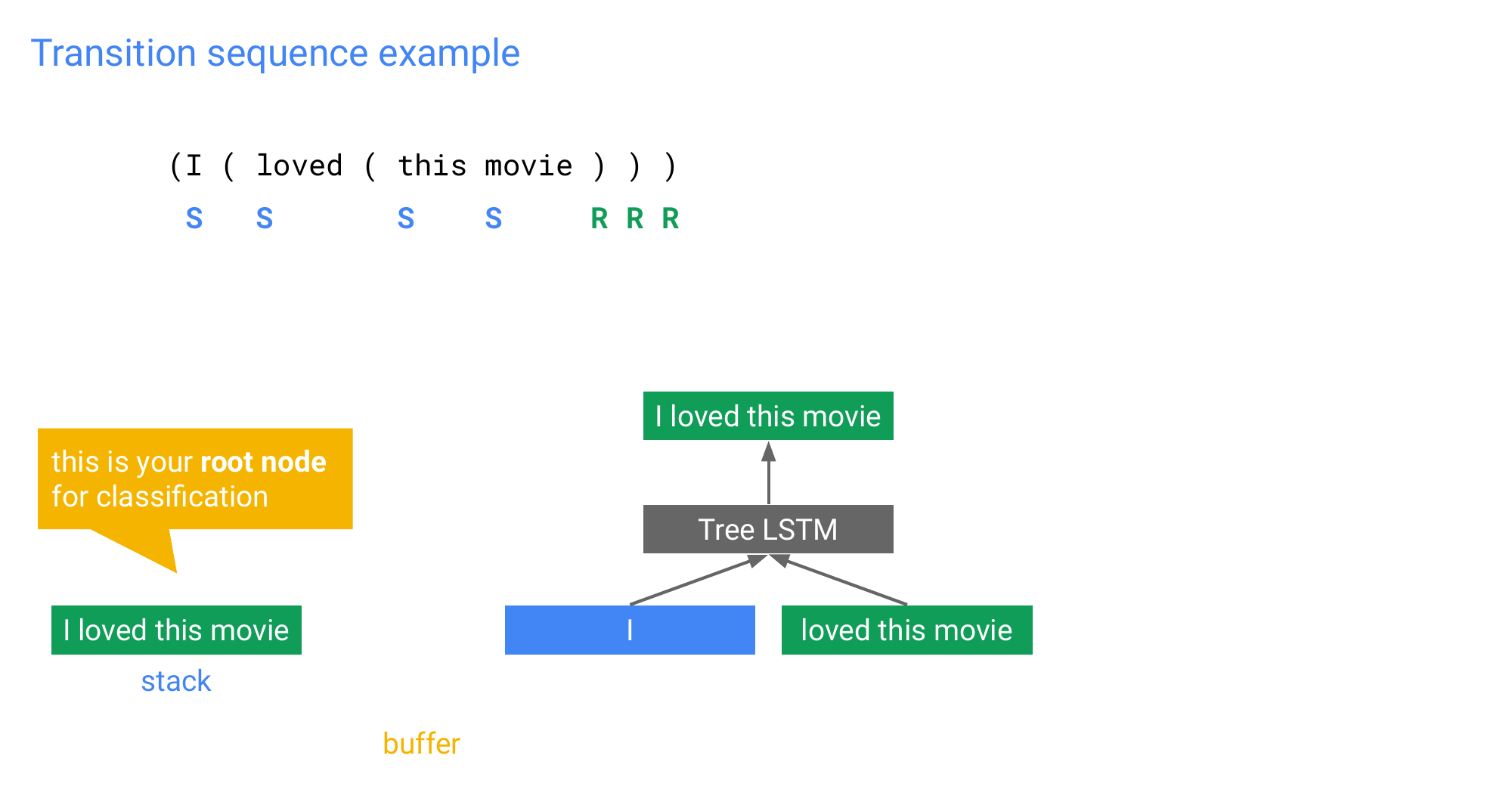
96 Transition sequence example
97 Title

Because we are doing this in sequence so putting thins on the stack and then to the tree we cannot dot his in parallel, so this is slow. Thus, we want to do mini-batch where you process multiple sentences at the same time and
98 Transition sequence example (mini-batched)

99 Transition sequence example (mini-batched)
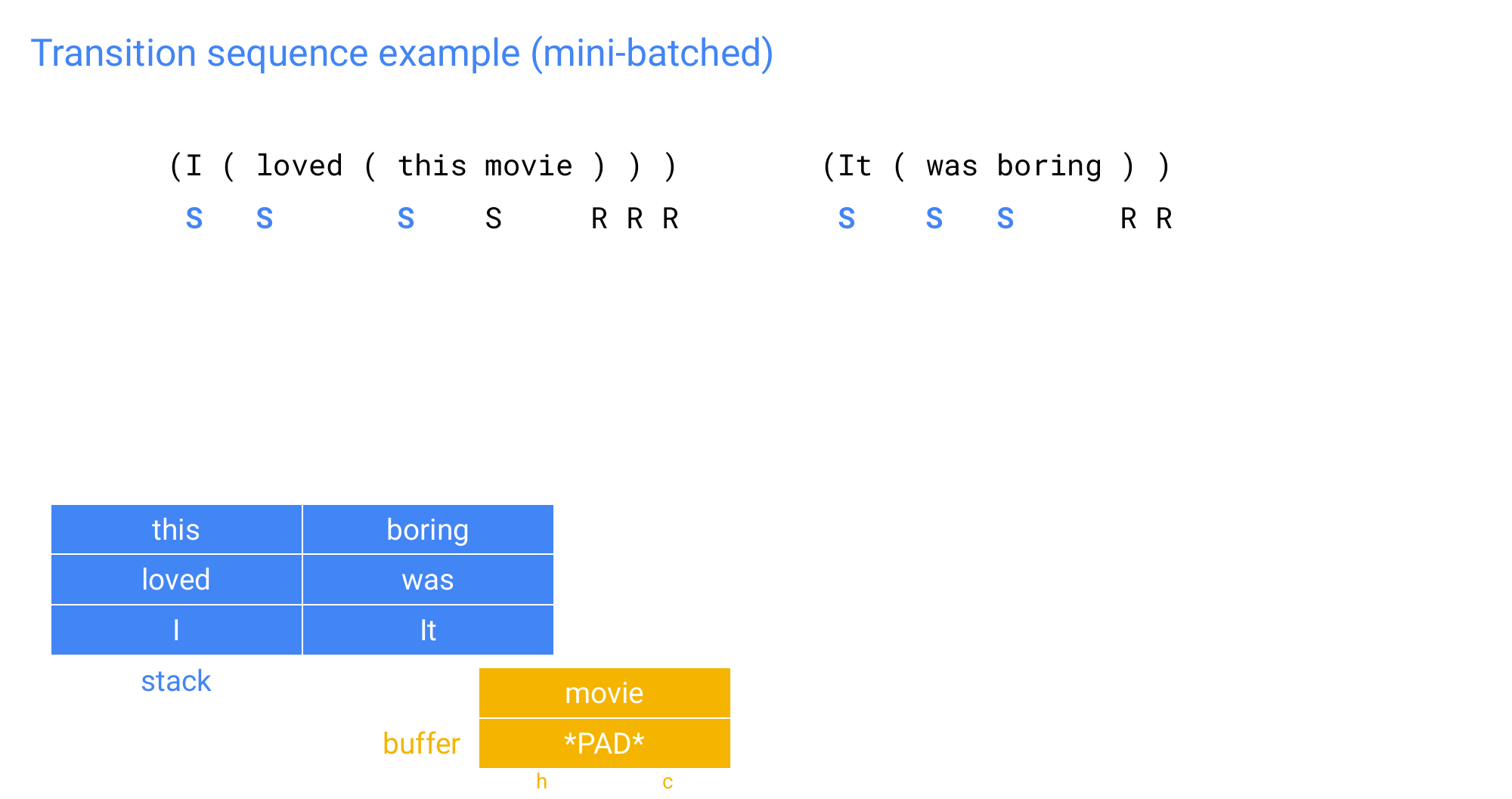
100 Transition sequence example (mini-batched)
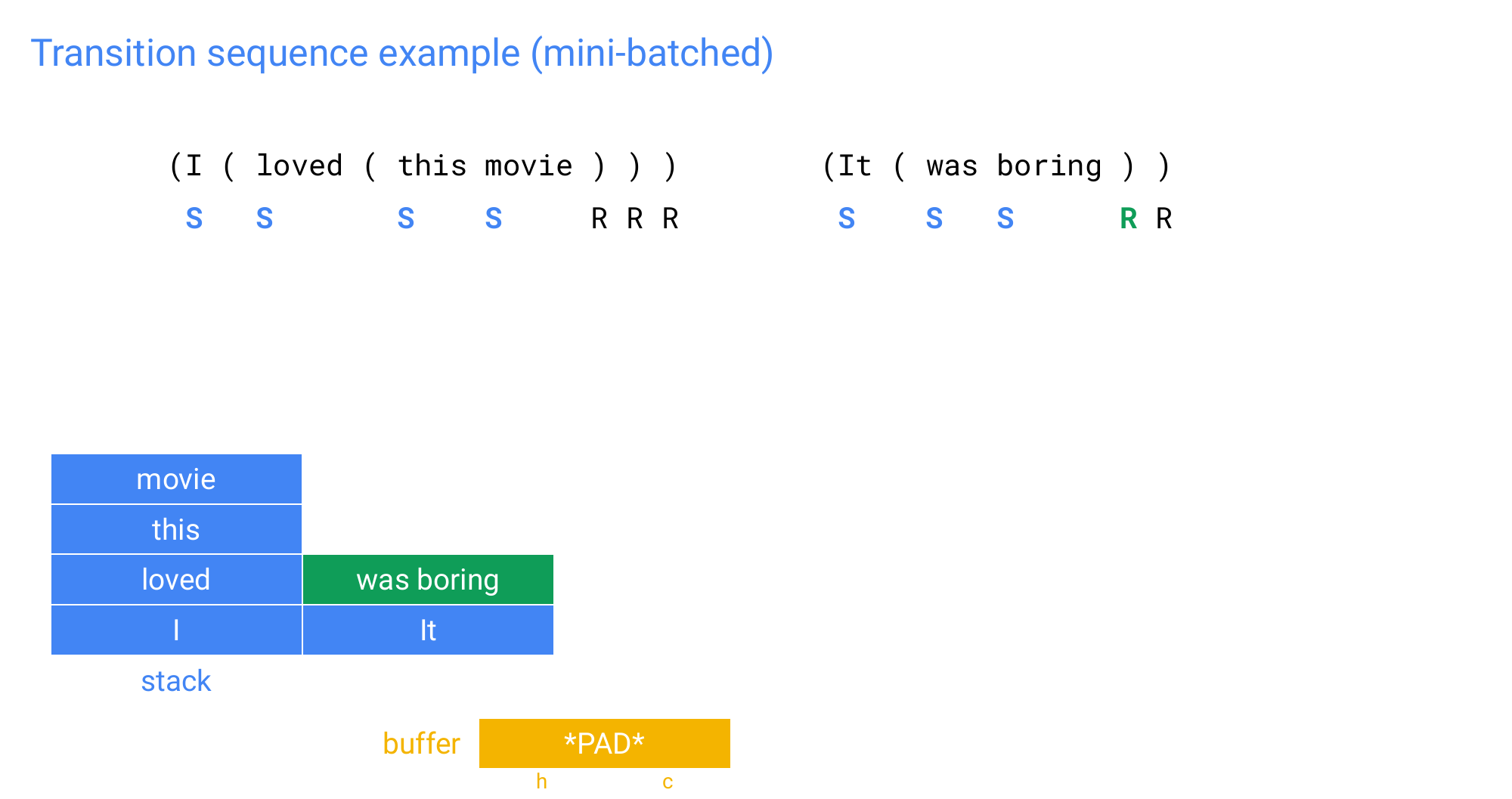
101 Transition sequence example (mini-batched)
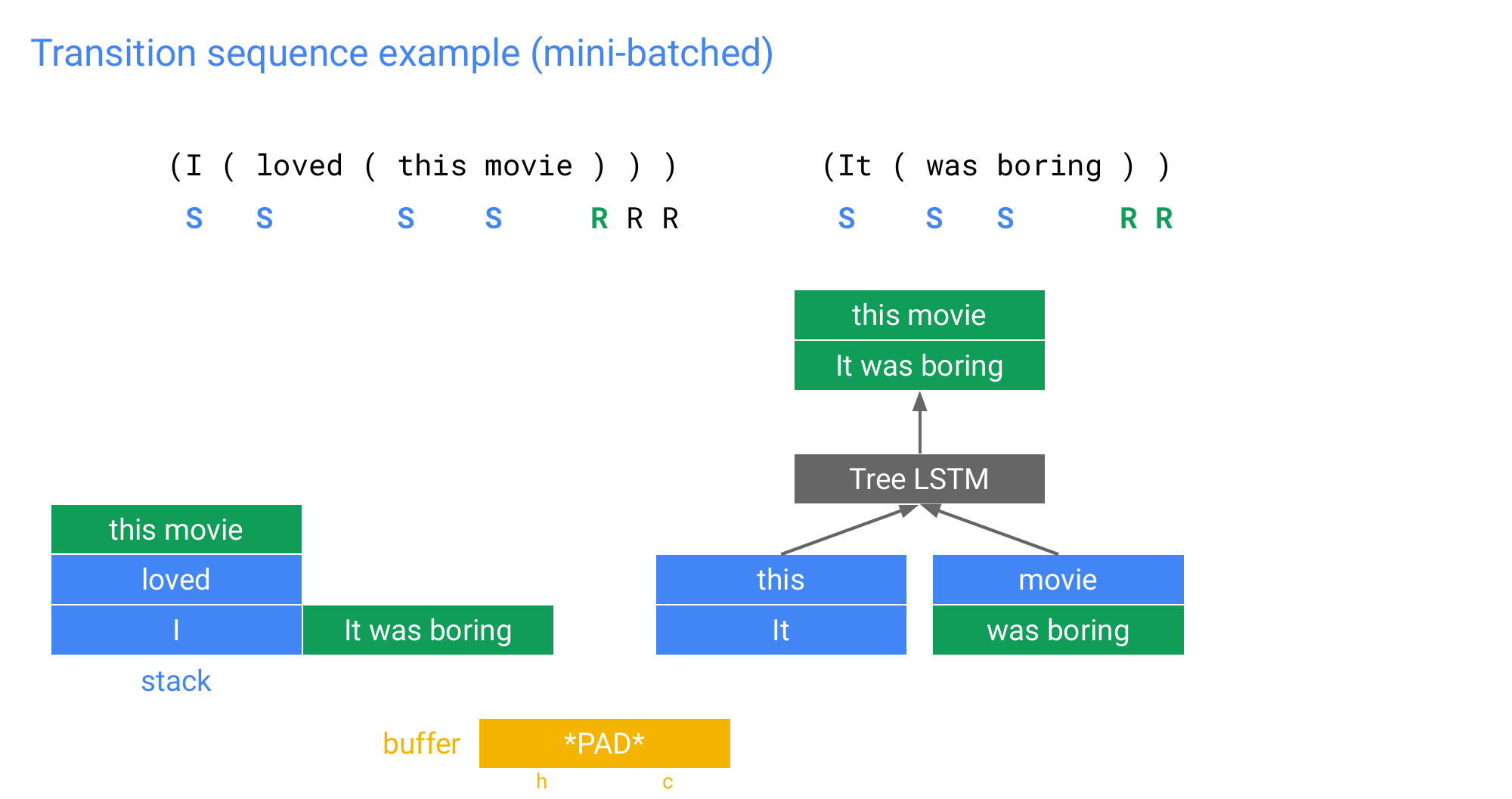
102 Transition sequence example (mini-batched)

103 Transition sequence example (mini-batched)

104 Optional approach: Sentence + Sentiment + Syntax + Node-level sentiment

105 Title

106 Recap

107 Title

108 Input

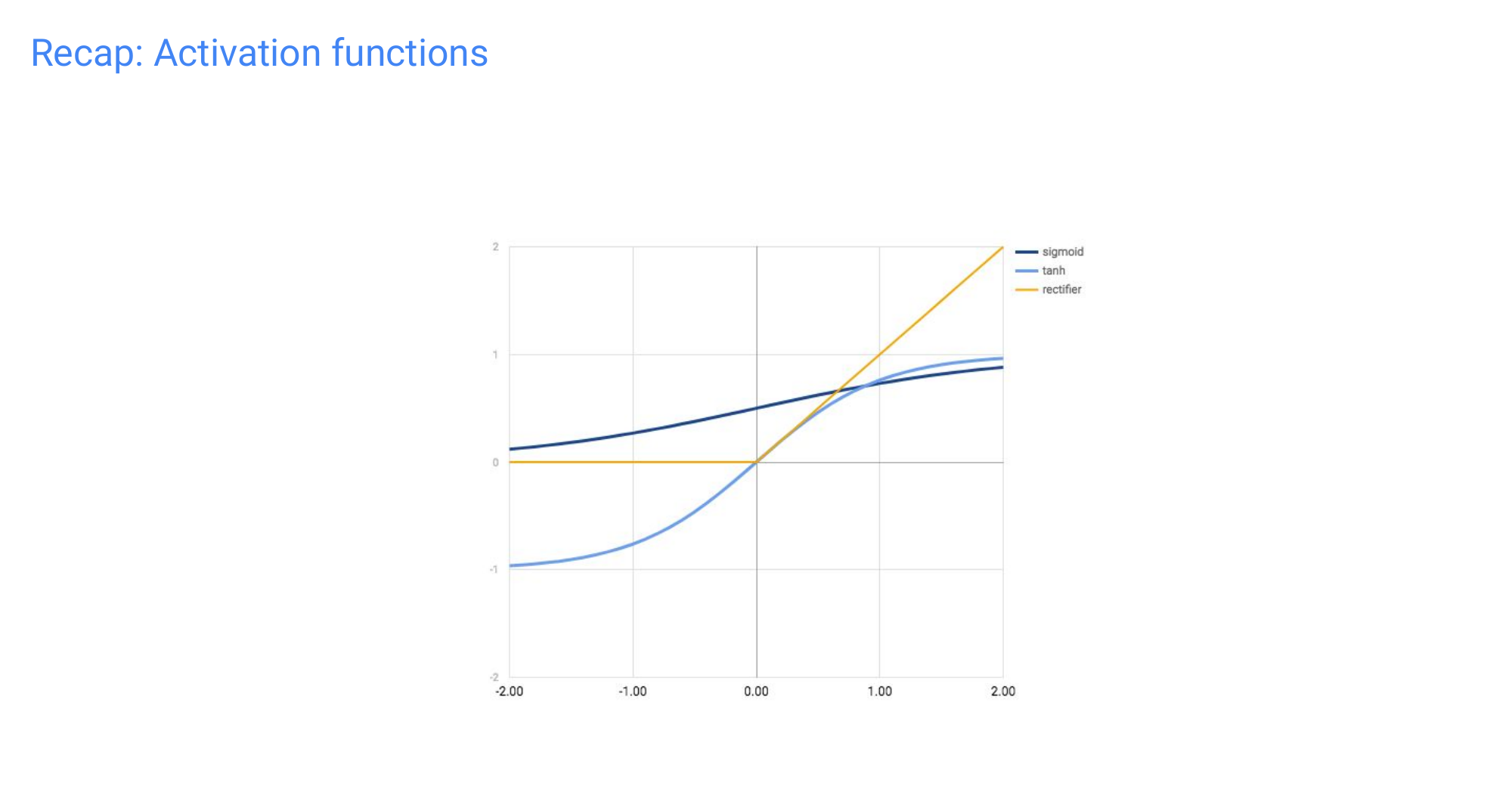
109 Recap: Activation functions
110 Introduction: Intuition to solving the vanishing gradient
111 Introduction: A small improvement
112 Child-Sum Tree LSTM

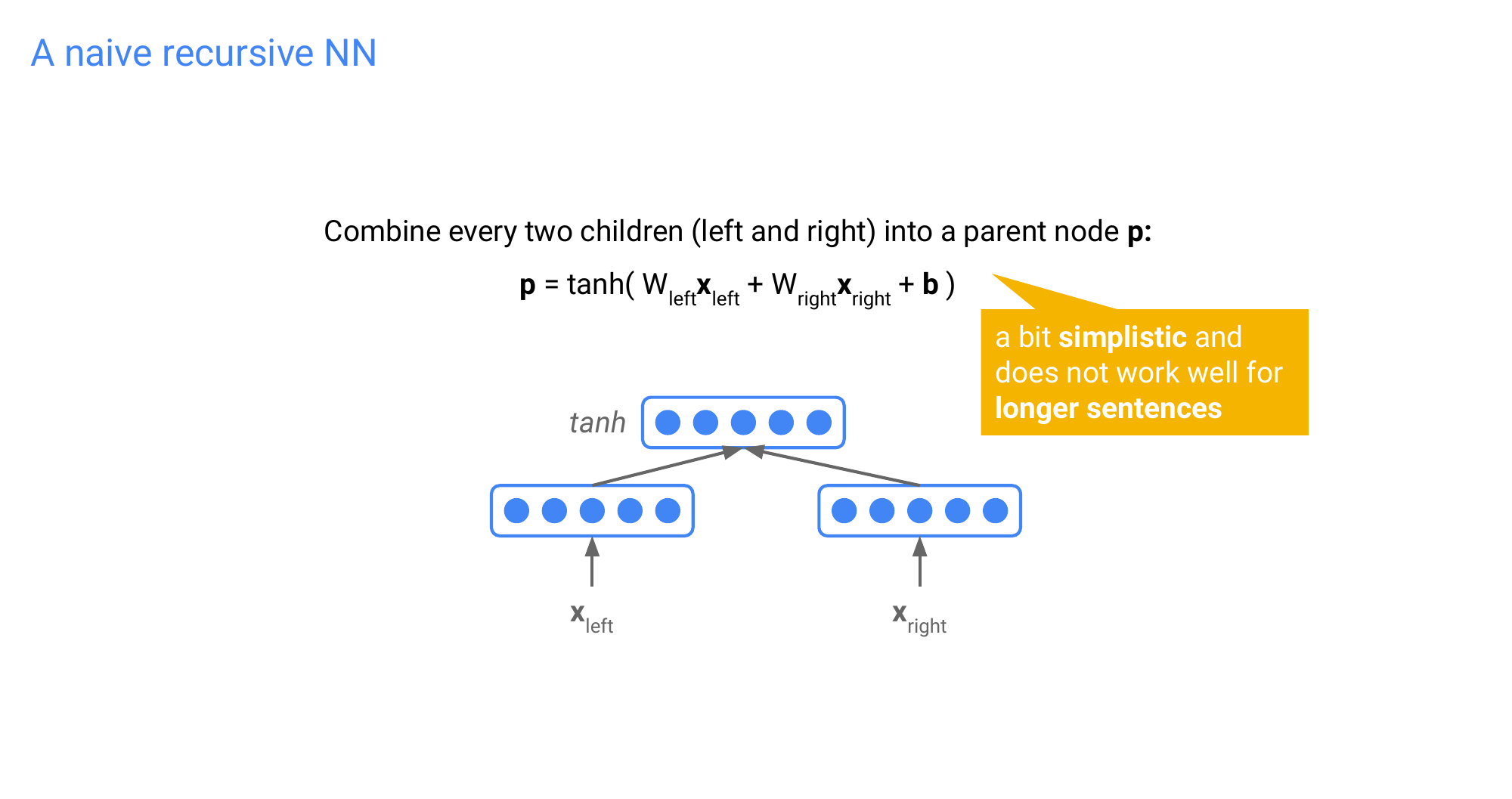
113 A naive recursive NN
114 SGD vs GD