1 Outline

2 Context
3 Definition

4 Definition
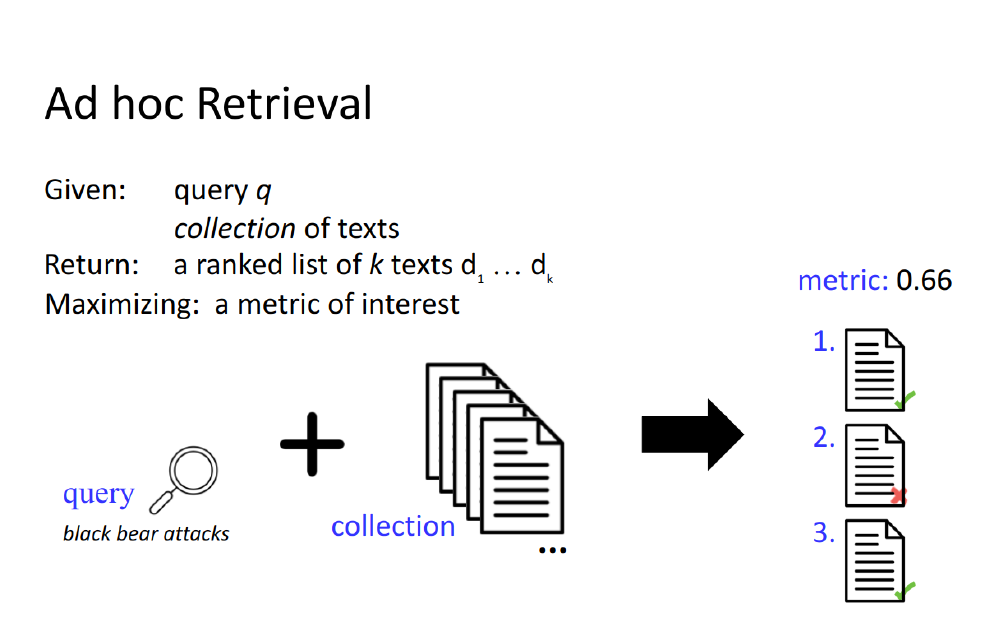
The collection of documents is what we found in the crawling phase.
We usually retrieved the top \(k\) best documents to look at
What does ad-hoc means?
Unlike predefined queries in some systems, ad hoc queries are formulated on-the-fly, reflecting the user’s immediate information need.
There is not fixed dataset. The collection of documents could be static but is often updated with new information.
5 Document: the unit of retrieval

Entity, you expect to get a movie name back or a wikipedia page to a movie. Entity is a proper noun, something that you will write with a capital letter i.e. ‘The Advangers’
6 Ranking problems

7 Ranking problems
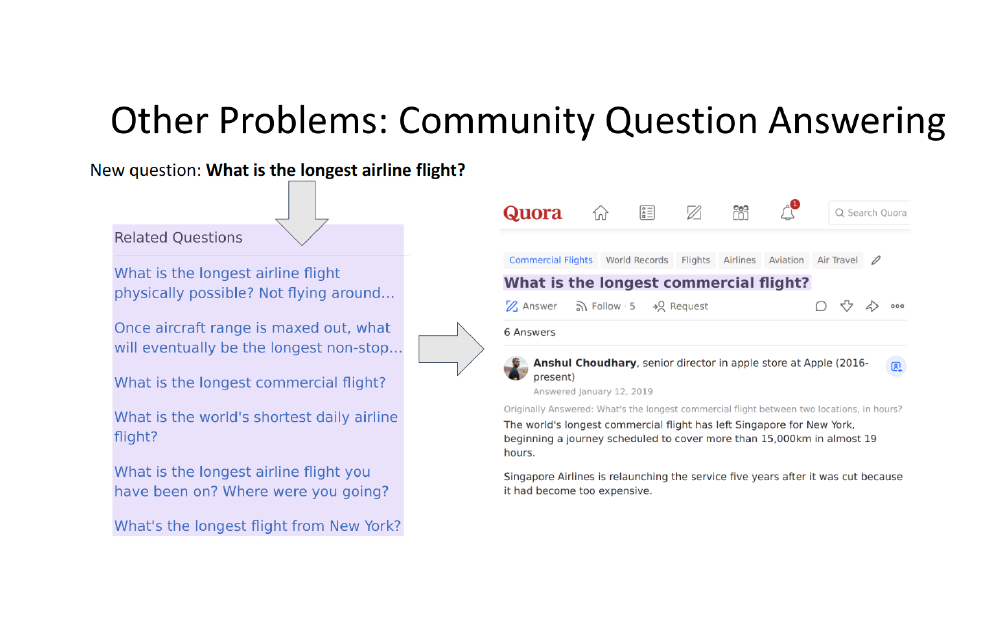
8 Ranking problems

9 Outline

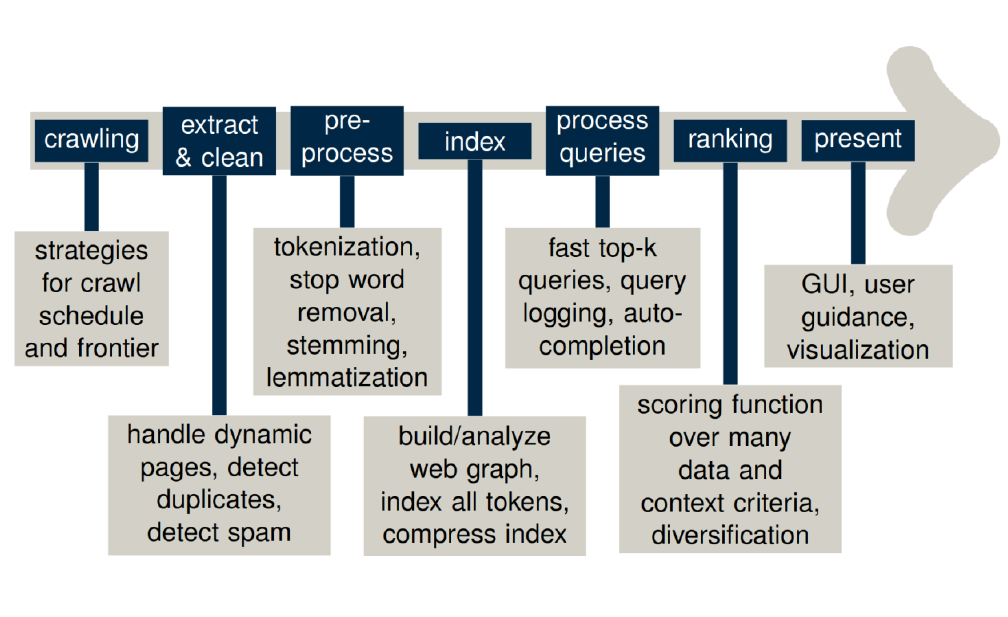
10 Document analysis pipeline

11 Query analysis pipeline

If document is lower cased and we upper case the query then the two strings will not match as far as the indexing is concerned and thus even though we may be looking for the same thing because one is lower cased then we will not be able to find this information.
12 Index types

After we do some pre-processing we put them into some index, and that index is what we use with the retrieval method
Inverted Index, maps from the term to the list of occurrences in the document.
Forward Index, we have some document ID and we return the document text. You can think of it has hash mapping from document ID to document text
Approximate Nearest Neighbor, Here we have a vector representation as the query. So rather than the tokens [‘raw’, ‘string’] as in Inverted Index, we have now a vector ie 100 dimensions. Given this vector representation we ask the Approximate Nearest Neighbor what are the closest matches with this vector. In practice is like saying which documents are closest to this vector, assuming that we have indexed document representations in the index
13 Index types

Inverted Index, these are methods that have sparce representation of a document. If you have say 100000 terms in your vocabulary, you will create a vector of 100000 to represent this vector. You would expect more dimensions in this vector would be zero because most terms do not occur in this specific document. For instance this document could be really long but only has 5000 unique terms.
In this method you start with a term and you want to know in which document that specific term occurs and your scoring would be based on thisApproximate Nearest Neighbor, given a query vector we return the approximately top matching document vectors.
Forward Index, we use this method when we want the document text. Imagine we have a sophisticated method were we want to know what the document originally looks like or what the tokens originally look like. So we need to look at that exact document’s text in order to use this method. You can also use this for snipping extraction
14 Ranking pipeline
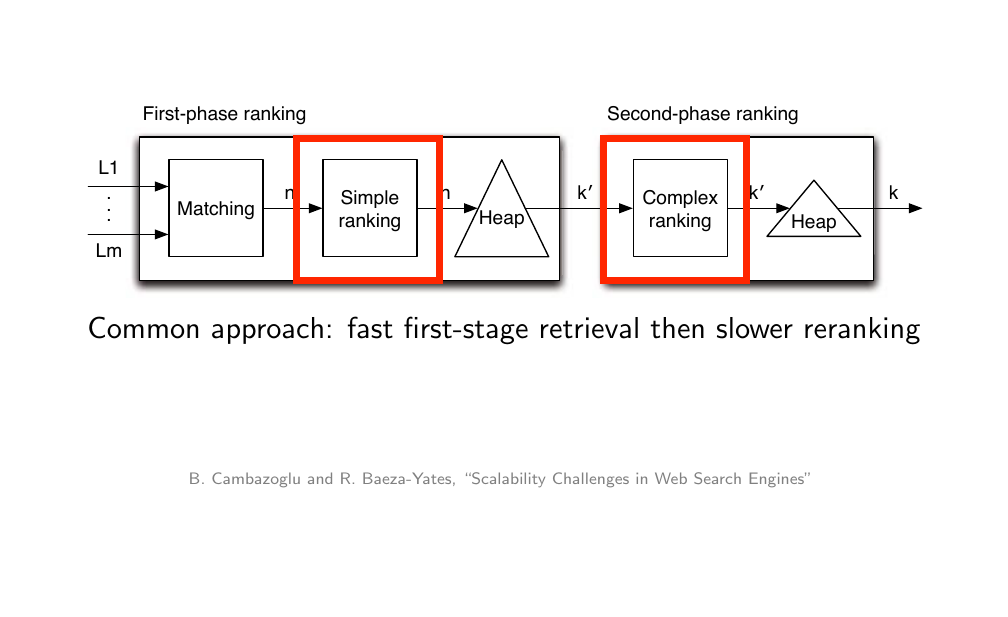
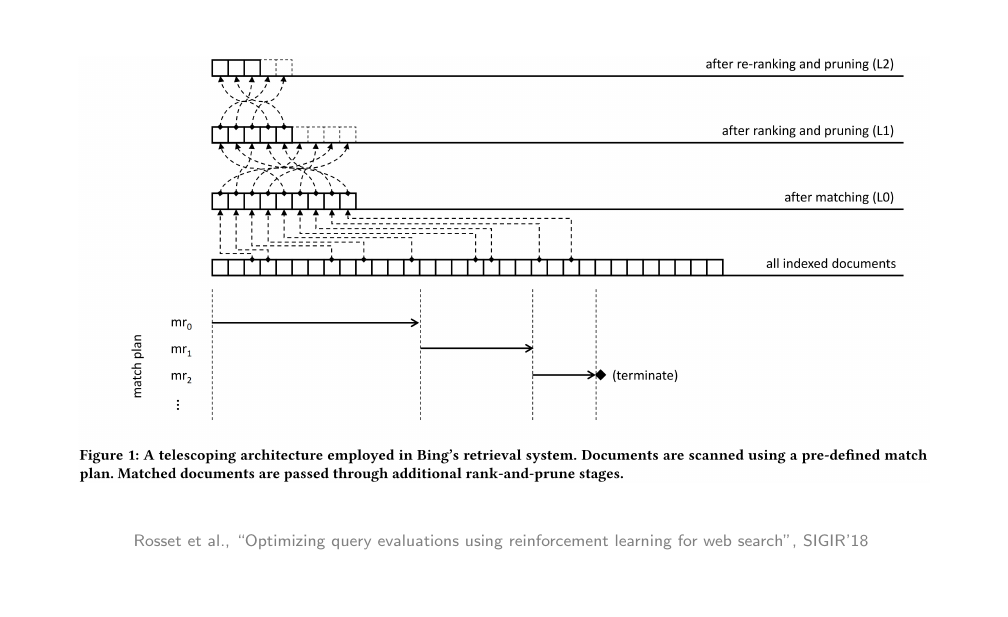
For instance we use the inverted index to find equals 10 000 top results based on a fast data structure. Then we use a much slower method to re-rank those 10 000 results. Possibly we return a subset
15 Ranking pipeline