1 Title

2 Document representation and matching
3 Outline

4 Outline

5 Documents as vectors

The documents are the columns. These columns are the vectors which are sparse. These are books. The rows are the characters
6 Match using cosine similarity

There is difference between cosine similarity and distance.
Similarity here a higher number is closer, this is just the dot product of the two vectors
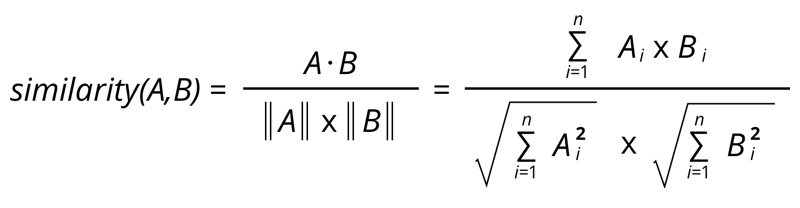
7 Term frequency
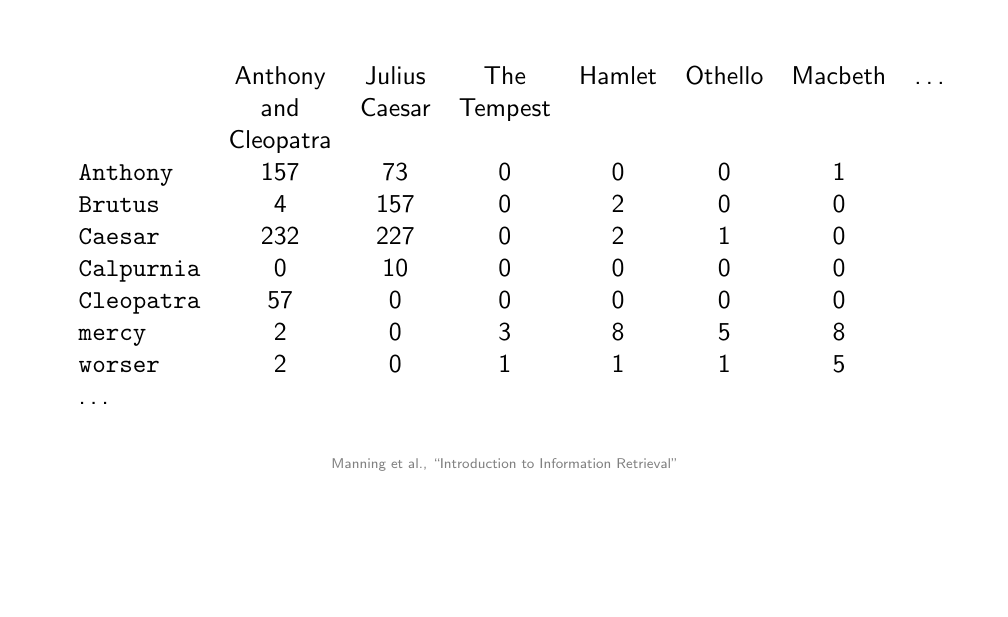
This is more helpfull because it tell us is how salient a token is in a document
8 Term frequency

\(tf_{t,d}\) is the frequency of token \(t\) in document \(d\)
9 Retrieval Axioms
9.1 TFC2
Signal, we see one term once and the diff on looking it 20 times. But imagine we have also a doc where there is 21 terms, then the log make it the same, because both have about 20 terms
We penalize with these scoping words, we want to penalize because we do not want to get a document whit many stop words
10 Slide 10
LNCs, No adding more pages, we prefer the one document has less documents
The query: University of Amsterdam, we want the terms of the query to be closer to each other
11 Inverse document frequency

In B25 assignment there is a more complicated on how to calculate \(IDF\).
Term frequency \(TF\), is a proxy for term’s importance in a document
Inverse document frequency \(IDF\), is a proxy for a term’s descriptiveness. So how happy should your ranking function be when you see this term.
- For instance the term ‘the’ not really happy, in contrast, ‘ipad 12X34’ very happy because this does not occur very much.
log(200/100) = 0,30in contrast to,log(200/1) = 2,30.
- For instance if you have a term that occurs in every document you would have
log(200/200) = 0
- For instance the term ‘the’ not really happy, in contrast, ‘ipad 12X34’ very happy because this does not occur very much.
\(df\) is the document frequency of token \(t\). For instance, token = ‘run’ df(run) = 8 documents, meaning the word ‘run’ appears in 8 documents
12 Inverse document frequency

Calpurnia is a very rare term that does not occur in all documents does, its \(IDF\) would be higuer
13 TF-IDF

One time versus twn times in the document, how likely we have seen that term in the document, so how useful is to find that term.
14 TF-IDF summary

15 Outline

16 Outline

17 Language model

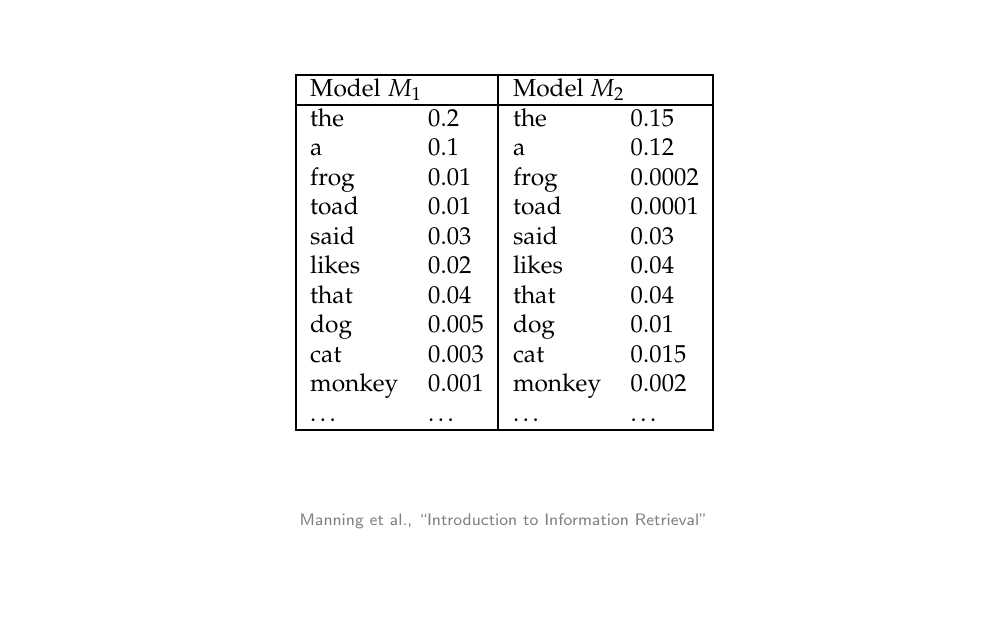
18 Unigram language model example
19 Documents as distributions

What if the term does not appear, int he document even thought we are talkinig about say hollad? We then will not retrieve this document which is clearly not the sace
20 Match using query likelihood model (QLM)

21 Match using KL-divergence
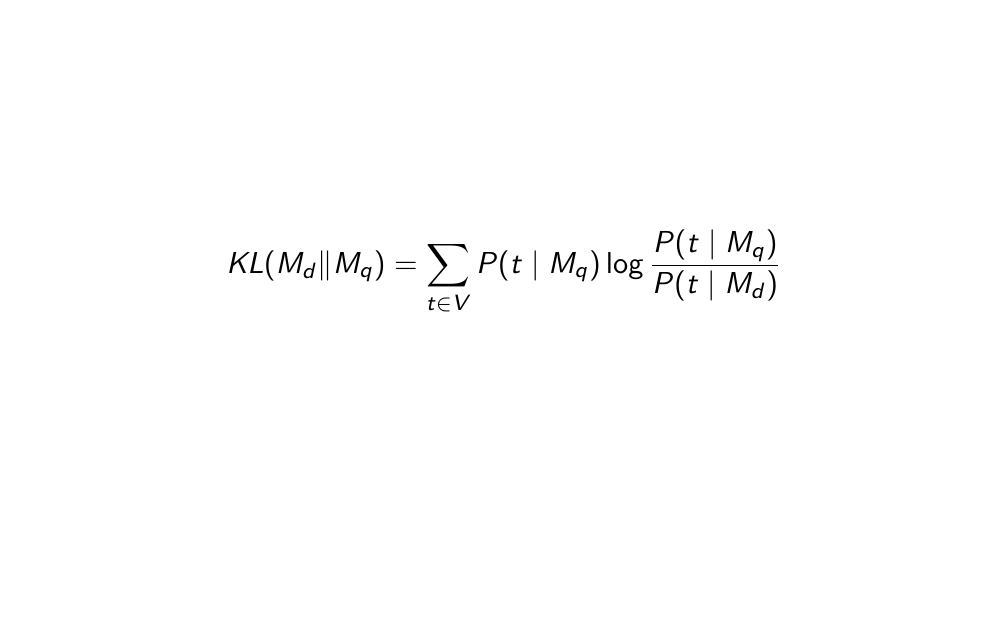
The lower the divergene the lower the similarity
22 Outline

23 Jelinek-Mercer smoothing

24 Dirichlet smoothing

25 Language modeling for IR summary

26 Outline

27 BM25

28 BM25
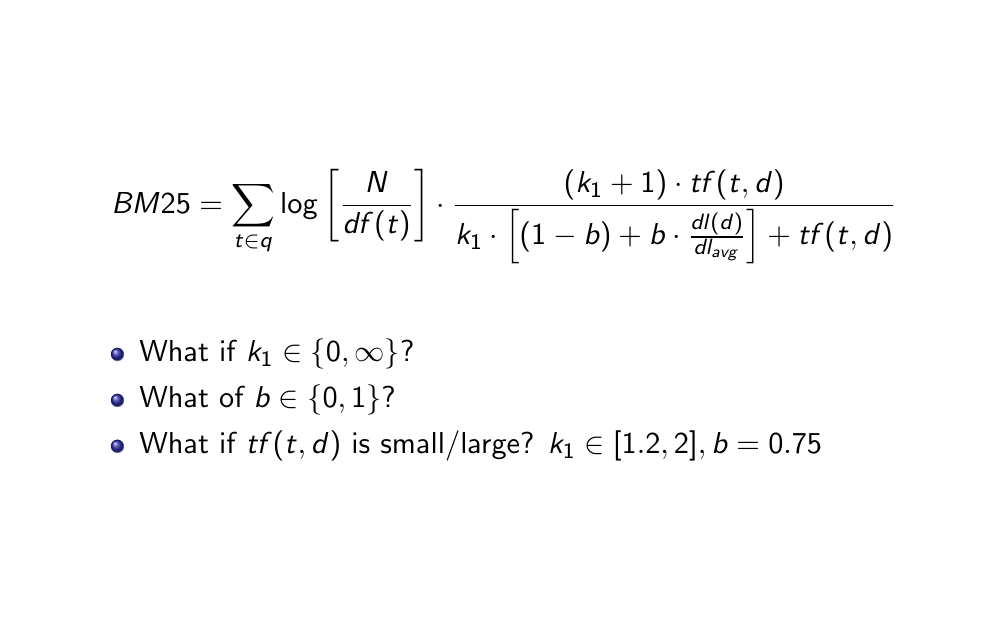
29 BM25 for long queries
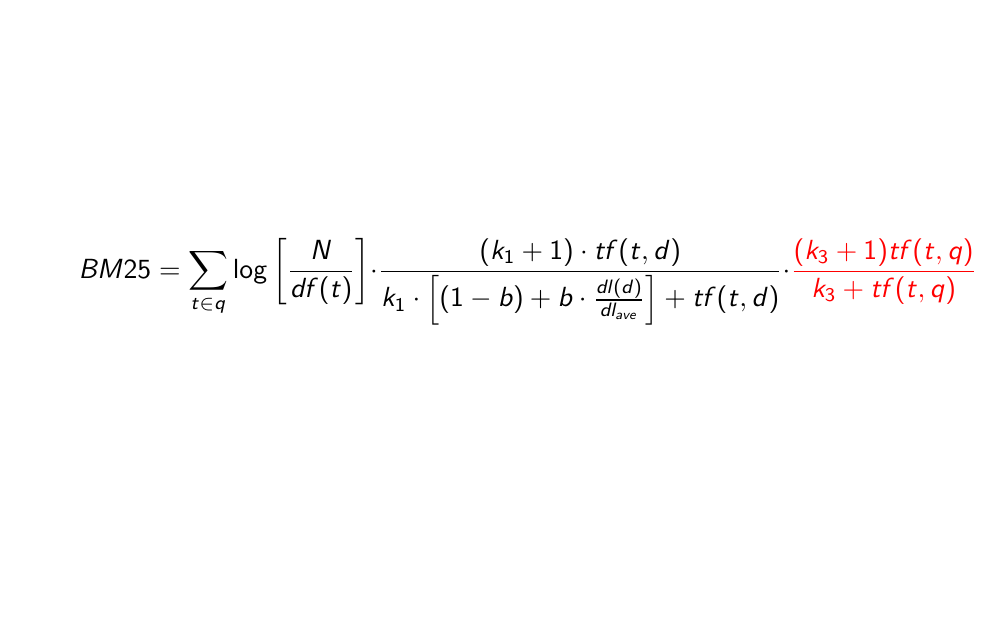
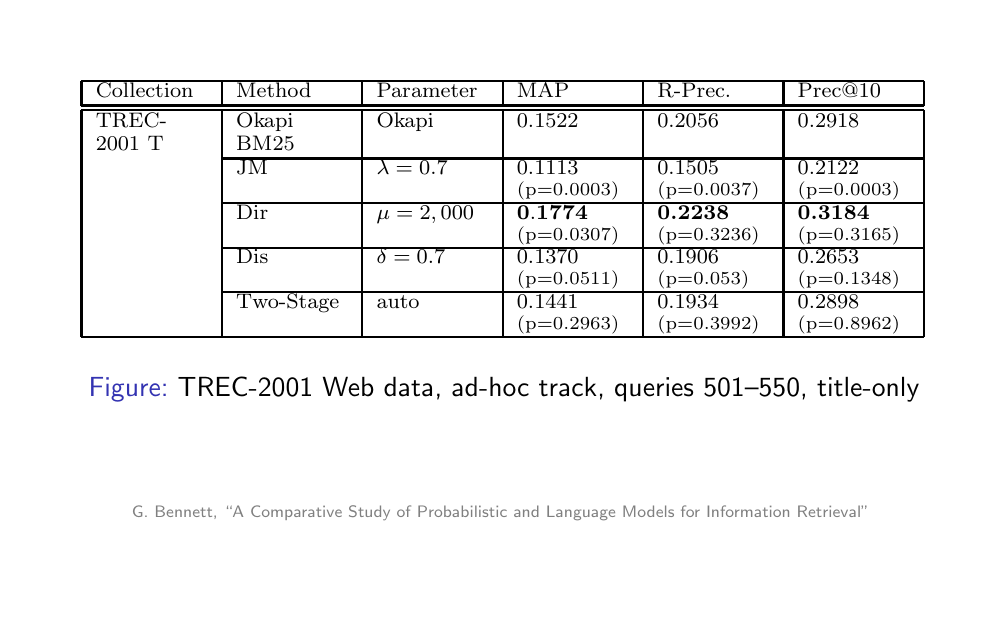
30 Experimental comparison
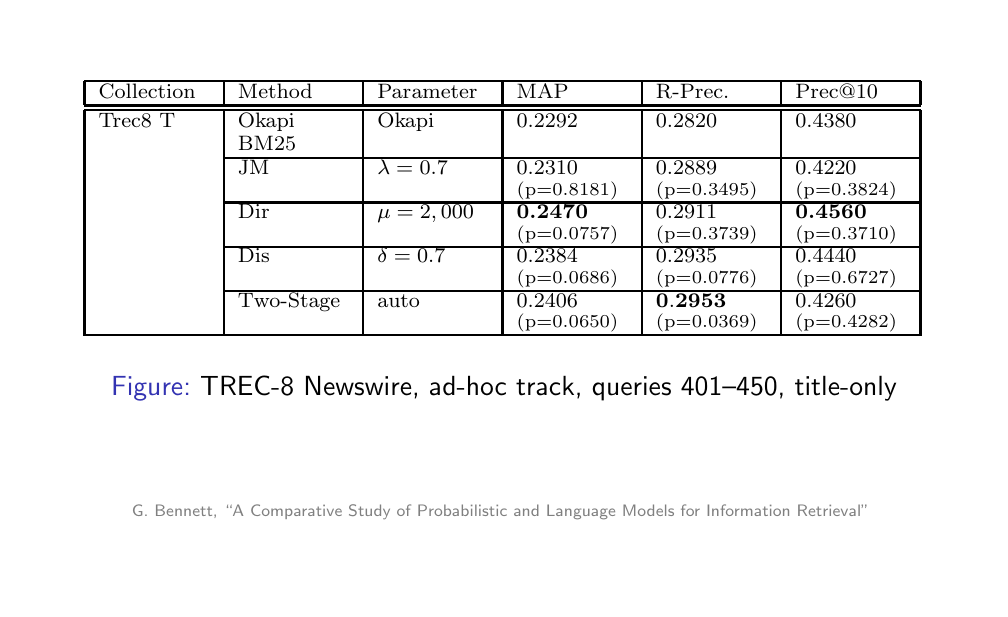
31 Experimental comparison
32 Content-based retrieval summary

33 Materials
